Complete System Design Interview Guide for Senior Developers (2026): The End-to-End Playbook (Framework + Checklists + Case Studies)
You spent 8 years shipping features. You know dependency injection inside out. Yet you just got rejected for an L6 role because your architecture was “hand-wavy.” This system design interview guide exists because brilliant developers fail system design interviews every single day. Not because they lack knowledge. Because they lack a framework. This is the definitive blueprint that transforms you from “guessing under pressure” to “architecting with confidence.”
Last updated: Feb. 2026
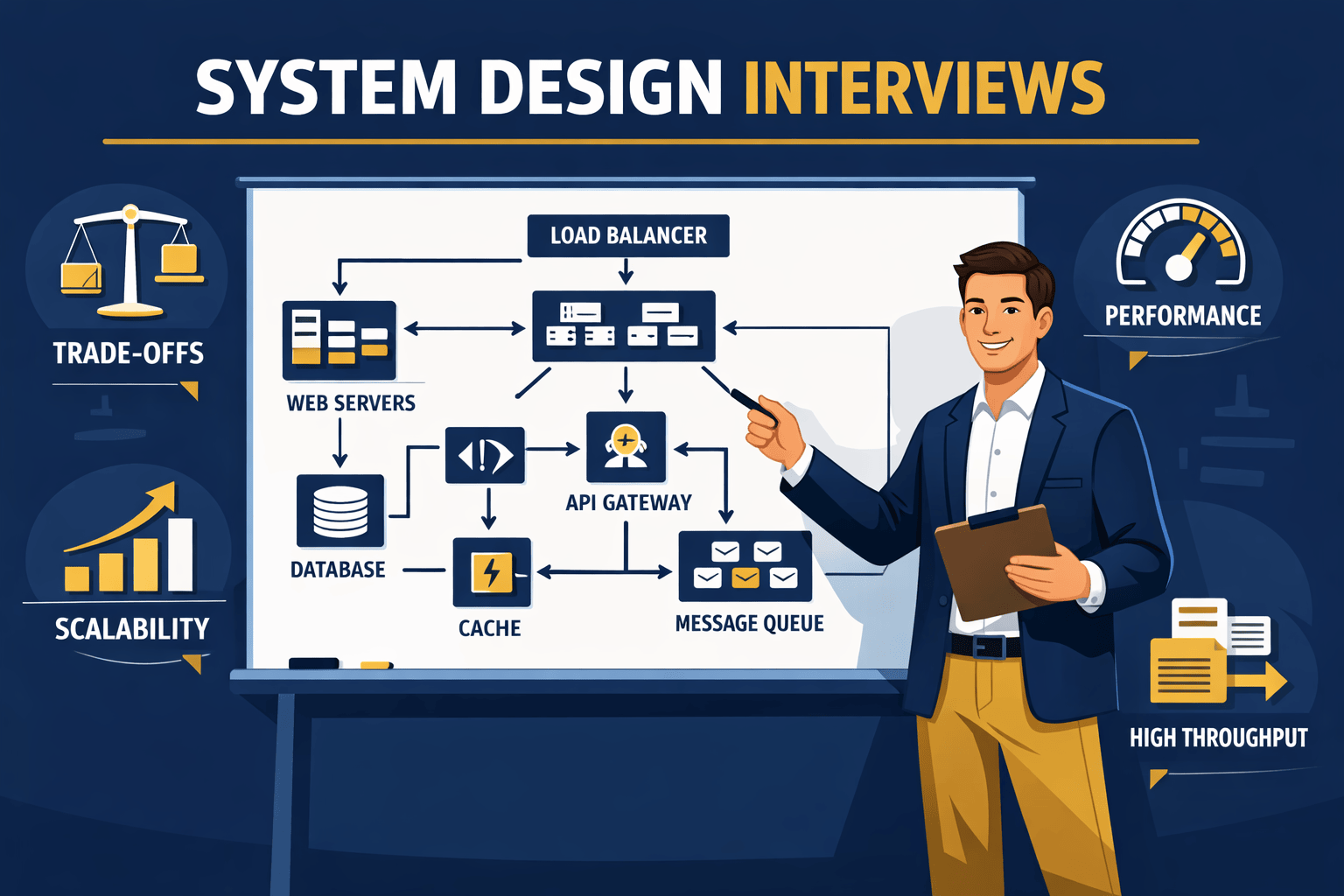
Table of Contents
- 1. The Senior Gap: Why Experienced Developers Struggle
- 2. The Evaluative Lens: What L6+ Actually Means
- 3. The 7-Step Universal Framework
- 4. Advanced “Awe/Depth” Modules
- 5. The Case Study Library
- 6. The 8-12 Week Preparation Roadmap
- 7. Resources & Strategic Next Steps
- 8. Your Path to Interview Success
- 9. FAQs
Contents
The Senior Gap: Why Experienced Developers Struggle with System Design
Picture this scenario. You walk into a system design interview with 8 years of .NET experience. You have shipped production systems handling millions of requests. You know Entity Framework Core, dependency injection, and microservices architecture. The interviewer asks you to design a URL shortener. Forty-five minutes later, you walk out wondering what went wrong.
This is the “Senior Gap.” It is the disconnect between building real systems and explaining how you would build them under interview pressure. Production experience and interview performance are surprisingly different skills.
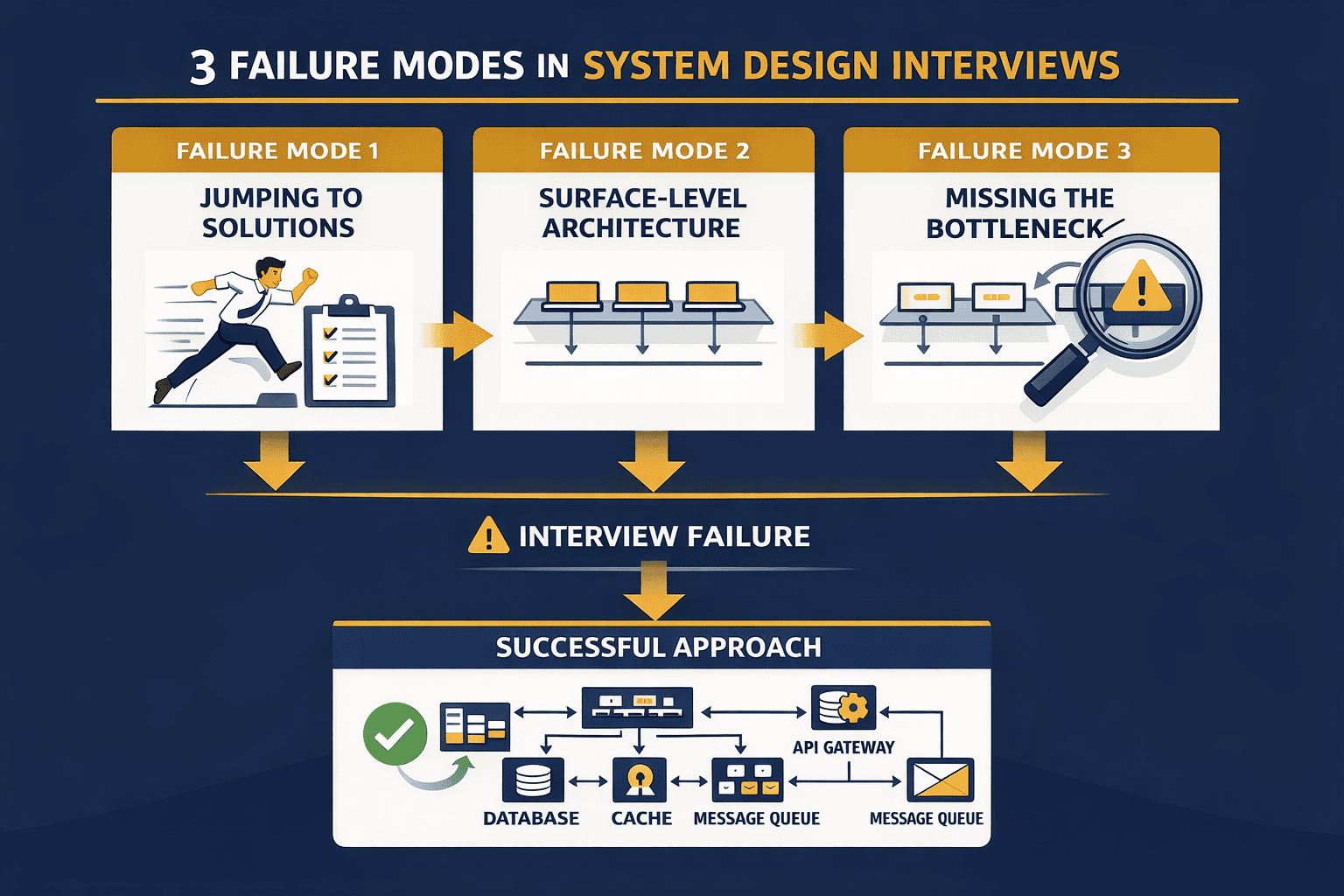
The Three Failure Modes
Senior developers fail system design interviews in predictable ways. The first failure mode is jumping straight to solutions . You hear “design Twitter” and immediately start drawing databases and message queues. The interviewer wanted to see you clarify requirements first. You skipped the most important part.
The second failure mode is surface-level architecture . You draw boxes and arrows. Load balancer here. Database there. Cache somewhere. But when the interviewer asks why you chose PostgreSQL over DynamoDB, you stumble. You never explained the trade-offs driving your decisions.
The third failure mode is missing the bottleneck . Every system has one critical component that determines success or failure. Senior interviewers probe that bottleneck relentlessly. If you cannot identify it and dive deep, you look like someone who has never operated systems at scale.
The Real Test
System design interviews do not test what you know. They test how you navigate ambiguity. Real projects have product managers writing specifications. Real projects have weeks to research solutions. Real projects allow you to prototype and iterate.
Interviews give you 45 minutes, a vague problem, and zero documentation. Your job is to demonstrate that you can structure chaos into a coherent architecture while explaining your reasoning clearly. This requires a framework.
The Mindset Shift
The most important change you must make is treating system design as a structured conversation rather than a technical exam. You are not proving you memorized consistent hashing. You are demonstrating that you can lead a technical discussion about building something complex.
Interviewers want to see how you think. They want to understand your decision-making process. They want evidence that you can collaborate with senior engineers on architectural decisions. The technical knowledge is table stakes. The communication and reasoning are what get you hired.
When you internalize this mindset, everything changes. You stop worrying about saying the “right answer” and start focusing on making your reasoning visible. That is what separates candidates who pass from candidates who fail.
The Evaluative Lens: What L6+ Actually Means
Before you learn the framework, you need to understand what interviewers are actually measuring. L6 and above evaluations are not about checking boxes on a technical checklist. They assess four distinct pillars that separate senior engineers from staff-level architects.
The Four Pillars of Senior Evaluation
Pillar 1: Product Ambiguity Resolution. Can you take a vague prompt and turn it into concrete requirements? When someone says “design a notification system,” a junior engineer starts drawing diagrams. A senior engineer asks about notification types, delivery guarantees, scale targets, and latency requirements. Your ability to scope the problem reveals your experience level.
Pillar 2: Trade-off Analysis . There are no silver bullets in distributed systems. Every choice has costs. When you choose eventual consistency, you gain availability but lose strong guarantees. When you add a cache layer, you improve latency but introduce complexity. Senior candidates make these trade-offs explicit and defend them.
Pillar 3: Technical Depth. Surface knowledge is not enough. When you say “we’ll use a message queue,” the interviewer will probe. What happens when the queue fills up? How do you handle duplicate messages? What consistency guarantees does your chosen queue provide? Depth means understanding the internals of your chosen components.
Pillar 4: Communication Quality. Technical interviews are conversations, not presentations. Senior candidates lead the discussion. They explain their reasoning before drawing boxes. They pause to check alignment with the interviewer. They adapt when given new constraints. This pillar often determines the final decision when technical skills are equal.
📊 Table: The Four Pillars Evaluation Matrix
This matrix shows what interviewers look for at each level. Use it to self-assess where you need the most improvement before your interviews.
| Pillar | Junior Signal | Senior Signal (L5-L6) | Staff Signal (L6+) |
|---|---|---|---|
| Product Ambiguity | Accepts requirements as given | Asks clarifying questions | Proactively identifies edge cases and constraints |
| Trade-off Analysis | Single solution without alternatives | Mentions trade-offs when prompted | Leads with trade-offs, presents multiple options |
| Technical Depth | Names technologies without details | Explains how components work | Discusses internals, failure modes, and optimizations |
| Communication | Reactive, waits for questions | Explains reasoning clearly | Leads discussion, checks alignment, adapts fluidly |
Beyond “How It Works” to “Why This, Not That”
The fundamental shift at senior levels is moving from description to justification. Junior engineers describe what components do. Senior engineers justify why those components were chosen over alternatives.
Consider this example. You are designing a rate limiter. A junior response says “we’ll use Redis to track request counts.” A senior response says “we have two options here. We could use Redis with sliding window counters, which gives us precision but requires more memory. Or we could use a token bucket algorithm, which is more memory-efficient but less precise. Given our requirement for 99th percentile accuracy, I recommend the sliding window approach.”
Notice the difference. The senior response demonstrates awareness of alternatives, explains the trade-offs, connects the decision to requirements, and makes a recommendation. This pattern applies to every architectural choice you make.
The Hidden Rubric
Most companies use scoring rubrics that interviewers do not share with candidates. While specific rubrics vary, they consistently evaluate the four pillars. Strong candidates demonstrate all four. Weak candidates might show technical depth but fail on communication. Or they communicate well but cannot resolve ambiguity.
Your preparation should target all four pillars equally. Many engineers focus exclusively on technical knowledge because it feels concrete and measurable. But the soft pillars—ambiguity resolution and communication—often carry equal weight in final decisions. Balance your practice across all dimensions.
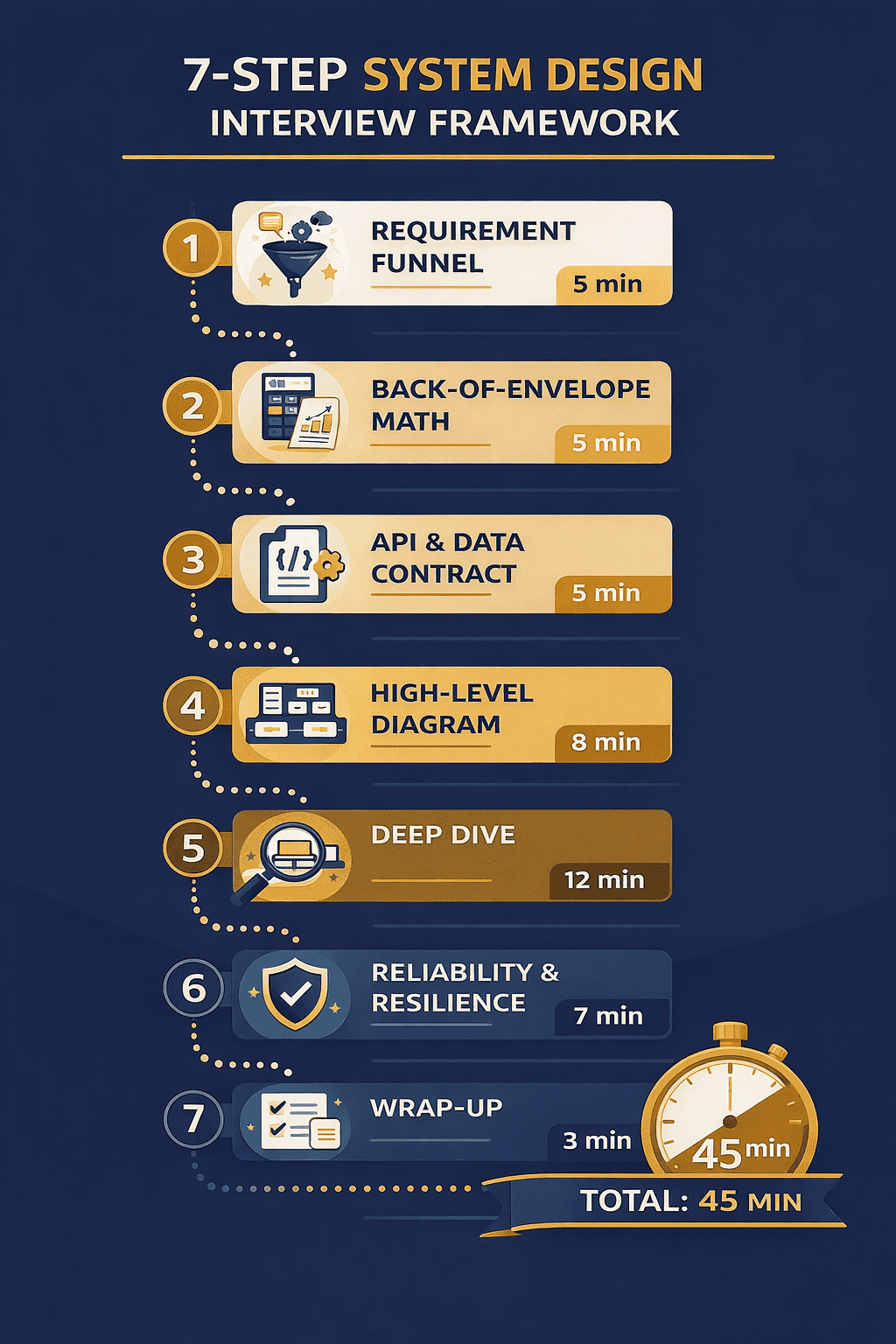
The 7-Step Universal Framework: Your Interview Blueprint
This is the core of your interview strategy. The 7-step framework provides a repeatable structure for any system design question. It ensures you cover all evaluation pillars while managing your 45-minute time budget effectively. Memorize this framework until it becomes automatic.
Step 1: The Requirement Funnel
Every interview begins with a deliberately vague prompt. “Design a URL shortener.” “Design Twitter.” “Design a notification system.” Your first job is to transform this ambiguity into concrete requirements through structured questioning.
Functional requirements define what the system does. For a URL shortener, these might include creating short URLs from long URLs, redirecting short URLs to original destinations, tracking click analytics, and supporting custom aliases. Spend 2-3 minutes capturing the core use cases.
Non-functional requirements define how the system performs. These include scale targets, latency expectations, availability requirements, and consistency needs. Most senior candidates fail here by not being specific enough. Do not say “the system should be fast.” Say “we need sub-100ms redirect latency at the 99th percentile.”
📥 Download: Requirement Funnel Question Template
This one-page checklist ensures you never miss critical requirement questions. Print it and practice until the questions become automatic. Covers functional requirements, non-functional requirements, and constraint clarification.
Download PDFA useful technique is the scale ladder . Ask about daily active users, requests per second, data storage growth, and geographic distribution. These numbers drive every subsequent decision. If you are designing for 10,000 users, your architecture looks completely different than designing for 10 million users.
Step 2: Back-of-the-Envelope Math
Capacity estimation is not about showing off your arithmetic skills. It is about making informed decisions. The numbers you calculate should directly influence your technology choices.
Start with traffic estimation. If you have 100 million daily active users and each user creates 2 short URLs per month, that is roughly 200 million writes per month, or about 77 writes per second. Reads are typically 100x more frequent than writes for URL shorteners, giving you 7,700 reads per second.
Then estimate storage. If each URL record is 500 bytes and you store 200 million new records per month, you need 100 GB of new storage monthly. Over 5 years, that is 6 TB. This tells you a single relational database can handle this if properly indexed, or you might want to consider a distributed storage solution for additional headroom.
The key insight is that math should inform architecture . Too many candidates perform calculations and then ignore them. If your math shows 10,000 writes per second, and you propose a single PostgreSQL instance, the interviewer knows you are not connecting the dots. Let your numbers drive your decisions visibly.
Step 3: API & Data Contract Design
Before drawing infrastructure diagrams, define your interfaces. The API contract establishes what your system exposes to the outside world. The data model determines how information flows internally. Getting these right constrains your architecture in productive ways.
For a URL shortener, your core API might include three endpoints. First, a POST endpoint to create short URLs that accepts the original URL and returns the shortened version. Second, a GET endpoint that takes a short code and redirects to the original URL. Third, a GET endpoint for analytics that returns click counts and metadata for a given short URL.
Define your data model with specific fields. A URL record might include the short code as primary key, the original URL, creation timestamp, expiration date, user ID if authenticated, and click count. Being explicit about your schema demonstrates that you understand what data you need to persist and query.
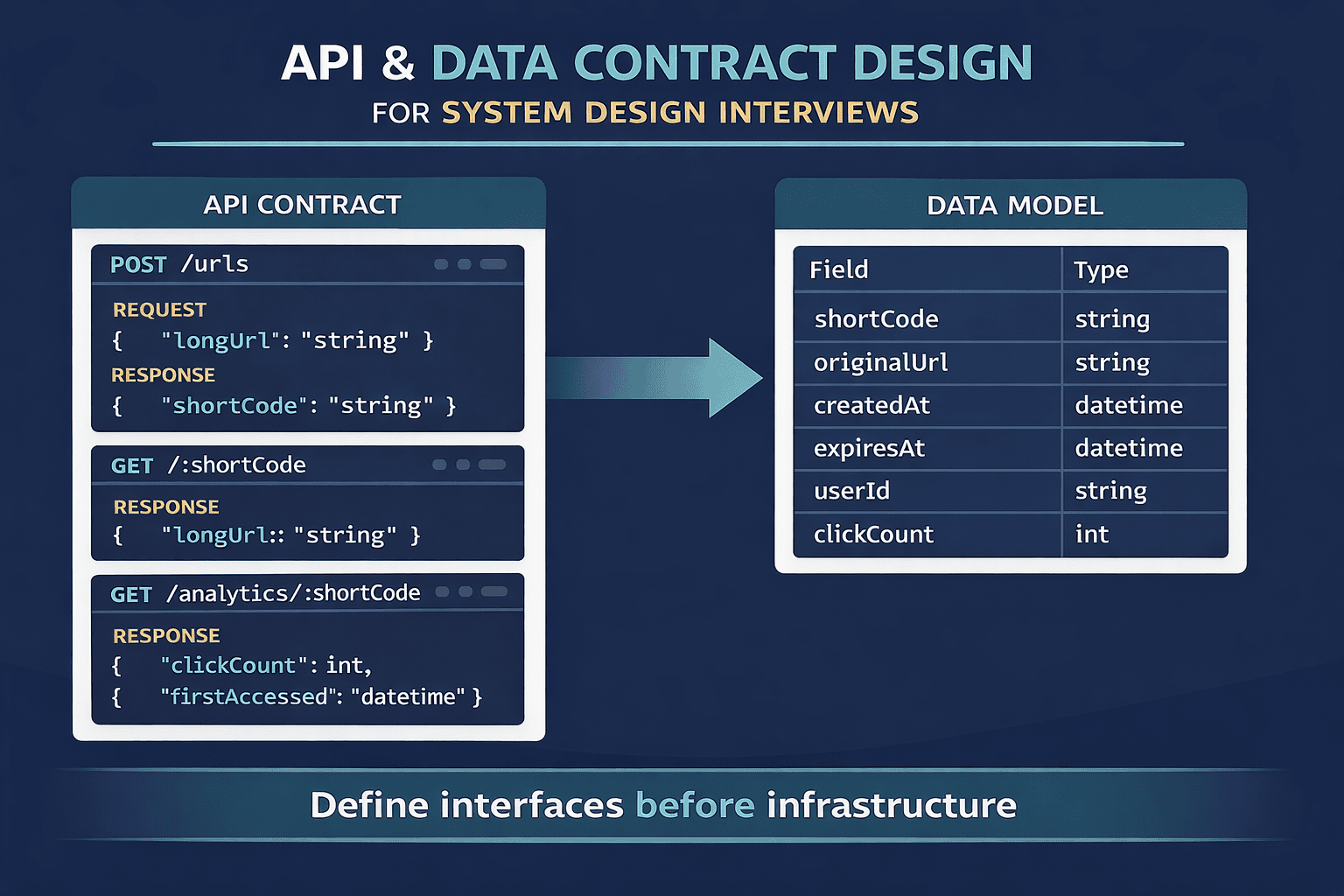
A critical technique here is thinking in queries . Consider what questions your system needs to answer. For URL shortening, you need fast lookups by short code. That means your short code should be indexed, likely as a primary key. If you also need analytics by user, you will need a secondary index on user ID. Let query patterns drive your data modeling decisions.
Step 4: High-Level Diagram (The Napkin Architecture)
Now you draw boxes and arrows. But do it strategically. Start with the simplest architecture that could possibly work. Then evolve it based on your requirements.
For most web systems, your initial sketch includes clients, a load balancer, application servers, a cache layer, and a database. Draw these components and the connections between them. Label each connection with the protocol or data type flowing through it.
The “napkin architecture” name is intentional. You should be able to sketch this on a napkin in 3-4 minutes. It is not meant to be comprehensive. It establishes a shared mental model between you and the interviewer. You will add complexity in subsequent steps.
Verbalize as you draw. Do not silently sketch for several minutes. Explain each component as you add it. “Users connect through our mobile and web clients. Traffic hits our load balancer, which distributes requests across our application tier. We have a Redis cache in front of our PostgreSQL database to handle read-heavy workloads.” This narration demonstrates your reasoning and invites feedback.
Step 5: The Deep Dive (Identifying and Solving the Bottleneck)
Every system has a bottleneck. A component that, if it fails or overloads, brings everything down. Your job is to identify this bottleneck and demonstrate deep knowledge about solving it. This is where senior candidates differentiate themselves.
For a URL shortener at scale, the bottleneck is typically read throughput . With 100:1 read-to-write ratio, your system processes far more redirects than URL creations. The database becomes the limiting factor because every redirect requires a lookup.
Solutions depend on your specific constraints. A caching strategy using Redis or Memcached can handle most reads without hitting the database. You might implement a multi-tier cache with application-level caching for extremely popular URLs and distributed caching for the long tail. For global scale, you could add geographic distribution with cache nodes in multiple regions.
📊 Table: Common Bottlenecks and Solutions by System Type
This reference table maps common system types to their typical bottlenecks and proven solutions. Use it to quickly identify where to focus your deep dive.
| System Type | Typical Bottleneck | Primary Solutions |
|---|---|---|
| URL Shortener | Read throughput | Multi-tier caching, CDN, read replicas |
| Social Feed | Fan-out complexity | Push vs. pull model, hybrid approach for celebrities |
| Chat System | Real-time delivery | WebSockets, message queues, presence service |
| Payment System | Consistency & idempotency | Two-phase commit, saga pattern, idempotency keys |
| Video Streaming | Bandwidth & storage | CDN, adaptive bitrate, chunked delivery |
| Search Engine | Index size & query latency | Inverted index, sharding, ranking optimization |
When diving deep, show your work . Do not just say “we’ll add caching.” Explain the cache invalidation strategy. Discuss cache-aside versus write-through patterns. Address what happens on cache misses. Talk about TTL policies and memory sizing. This level of detail signals genuine experience with production systems.
Step 6: Reliability & Resilience
Senior candidates think beyond the happy path. What happens when components fail? What happens when an entire region goes dark? Interviewers probe these scenarios to assess your operational maturity.
Start with single points of failure . Look at your architecture and identify any component where failure would cause complete system unavailability. Your database is often the biggest risk. Solutions include primary-replica setups with automatic failover, multi-region deployment for disaster recovery, and regular backup testing.
Consider graceful degradation . If your cache layer fails, can your system still serve requests? It might be slower, but it should not crash. If your analytics service is down, the core redirect functionality should continue working. Design for partial failure rather than all-or-nothing availability.
Address data durability . How do you ensure data is not lost? Discuss replication strategies, backup frequency, and recovery point objectives. For a URL shortener, losing the mapping between short codes and original URLs would be catastrophic. Your storage strategy must account for this.
Step 7: The Wrap-Up (Summarizing Trade-offs)
With 3-5 minutes remaining, shift to summary mode. This is your chance to demonstrate that you understand the full picture and can communicate it concisely.
Structure your wrap-up around three elements. First, restate the key requirements you addressed. “We designed a URL shortener handling 10 million daily active users with sub-100ms redirect latency and 99.9% availability.” Second, highlight your major design decisions . “We chose PostgreSQL for its ACID guarantees on writes, Redis for caching the hot set, and a consistent hashing scheme for future horizontal scaling.” Third, acknowledge trade-offs and limitations . “We traded some write latency for consistency by using synchronous replication. If analytics requirements grow, we might need a dedicated time-series database.”
The wrap-up also invites further discussion. You might mention areas you would explore with more time. “Given another 15 minutes, I’d want to dive deeper into our sharding strategy and discuss how we’d handle short code collision at scale.” This signals awareness of complexity without pretending you covered everything.
Advanced “Awe/Depth” Modules: The Differentiators
The 7-step framework gets you to “competent.” These advanced modules elevate you to “impressive.” When you demonstrate deep knowledge in these areas, interviewers remember you. This is where candidates competing for L6+ roles separate themselves from the pack.
The Data Dilemma: Consistency Models Deep Dive
Every distributed system makes trade-offs around data consistency. Understanding these trade-offs at a deep level signals genuine expertise. Most candidates can recite CAP theorem. Few can explain when to choose eventual consistency over strong consistency with concrete examples.
Linearizability provides the strongest guarantees. Every read returns the most recent write. This is what single-node databases give you naturally. In distributed systems, achieving linearizability requires coordination protocols like Raft or Paxos. The cost is latency and availability during network partitions.
Eventual consistency relaxes these guarantees. Writes propagate asynchronously. Different nodes may return different values temporarily. The benefit is higher availability and lower latency. Systems like DynamoDB and Cassandra default to this model.
The key insight is that consistency requirements vary by operation . A banking transfer needs strong consistency. A social media like count can tolerate eventual consistency. Many systems use different consistency levels for different data types. Being able to articulate when each model is appropriate demonstrates architectural maturity.
The “Killer” Edge Cases
Interviewers love probing edge cases because they reveal whether you have operated systems at scale. Three edge cases appear repeatedly across different system types.
The Hot Key Problem (The Justin Bieber Problem). What happens when one key receives disproportionate traffic? If Justin Bieber tweets and millions of users simultaneously request his timeline, that single database partition becomes overwhelmed. Solutions include request coalescing, where duplicate requests are merged, and hot key replication, where popular keys are copied to multiple cache nodes. You can also implement rate limiting strategies to protect backend systems from traffic spikes.
Thundering Herd. When a cache entry expires, hundreds of simultaneous requests might hit your database trying to repopulate the cache. This can cascade into database overload. Solutions include cache stampede prevention using probabilistic early expiration, request coalescing at the cache layer, and background cache refresh before expiration.
Cascading Failures. One failing component causes other components to fail. A slow database causes application threads to back up. Backed-up threads exhaust connection pools. Exhausted connection pools cause load balancers to mark servers as unhealthy. Suddenly your entire system is down. Circuit breakers, timeouts, and bulkheads prevent these cascades.

Microservices vs. Monolith: When Not to Distribute
Experienced architects know that distributed systems add complexity. Sometimes the right answer is simpler than candidates assume. Being able to argue against unnecessary distribution demonstrates mature judgment.
Start with a monolith when: Your team is small, under 10 engineers. Your scale requirements are moderate, under 10,000 requests per second. Your domain boundaries are unclear and still evolving. You are building an MVP where speed to market matters most.
Move to microservices when: Team size requires independent deployment cycles. Different components have different scaling requirements. You need technology diversity, different languages or databases for different services. Fault isolation is critical, one service failing should not bring down others.
The controversial but accurate truth is that most systems are over-distributed . Engineers reach for microservices because they are fashionable, not because they are necessary. In an interview, demonstrating restraint by recommending a simpler architecture when appropriate shows you understand the true costs of distribution.
The Case Study Library: Pattern Recognition Through Real Systems
Theory only takes you so far. To truly internalize system design, you need to study real systems and understand the patterns that emerge repeatedly. This case study library covers three archetypal systems that represent the most common interview categories. Master these, and you will recognize the underlying patterns in any problem you encounter.
Want guided practice? Start with these two interview-style case studies: Design Notification System (real-time + delivery guarantees) and Design File Storage System (Dropbox/Drive pattern: uploads, metadata, consistency).
Case Study 1: Global Scale Video Streaming (Netflix/YouTube Pattern)
Video streaming represents the ultimate challenge in bandwidth and storage management. When millions of users simultaneously stream high-definition video, every architectural decision has massive cost and performance implications.
The Core Challenge: Delivering terabytes of video data to globally distributed users with minimal buffering and acceptable quality. A single popular show can generate petabytes of traffic during peak hours.
Key Architectural Components: The system requires several specialized layers working together. Content ingestion handles uploading and processing raw video files. Transcoding converts videos into multiple resolutions and formats for different devices. A content delivery network positions video chunks geographically close to users. The recommendation engine personalizes what users see. The playback service coordinates everything during streaming.
The Critical Trade-off: Storage cost versus transcoding cost versus delivery latency. Pre-transcoding everything means massive storage bills but instant playback. On-demand transcoding saves storage but adds latency. The solution is tiered transcoding . Popular content gets pre-transcoded to all formats. Long-tail content gets transcoded on first request and cached.
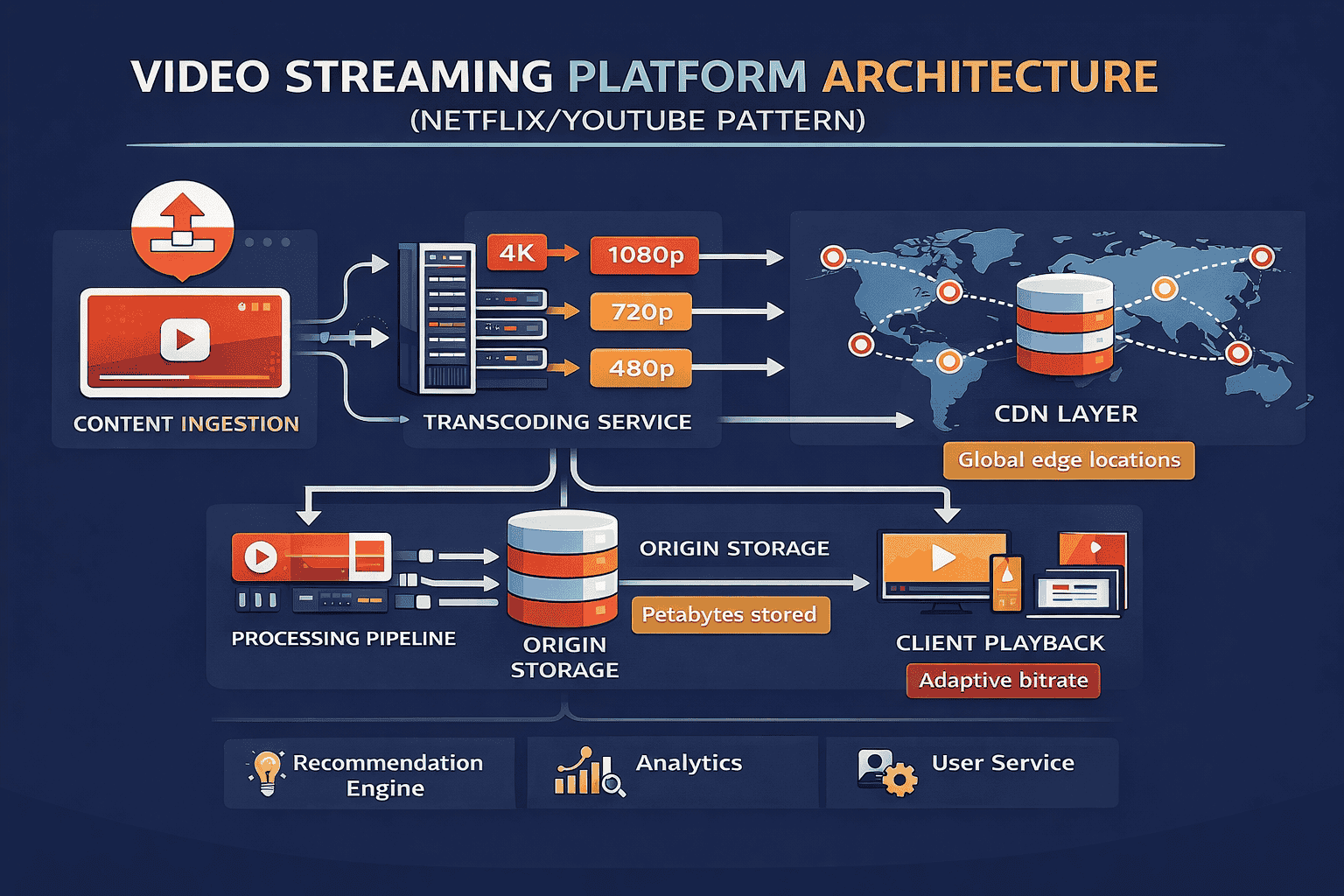
Deep Dive Area: Adaptive bitrate streaming. The client continuously monitors network conditions and requests appropriate quality chunks. This requires the video to be split into small segments, typically 2-10 seconds each, at multiple quality levels. The manifest file tells the client what segments are available. HLS and DASH are the dominant protocols. Understanding this mechanism demonstrates you know how streaming actually works, not just the high-level boxes.
Case Study 2: High Concurrency Flash Sale System (Ticketing Pattern)
Flash sales and ticket systems face a unique challenge. Massive traffic spikes concentrated in seconds. Limited inventory that must not be oversold. Users who will abandon if the experience is slow. This pattern appears in concert tickets, limited product drops, and auction systems.
The Core Challenge: Handling 100,000+ requests per second for a limited inventory of perhaps 10,000 items, while ensuring exactly-once purchase semantics and sub-second response times.
Key Architectural Components: A traffic management layer using queuing and rate limiting prevents backend overload. The inventory service tracks available stock with strong consistency guarantees. The reservation system holds items temporarily during checkout. The payment integration handles financial transactions. The notification service confirms purchases.
The Critical Trade-off: User experience versus inventory accuracy. Showing “available” when items might sell out creates bad experiences. Being too conservative means legitimate buyers see “sold out” prematurely. The solution involves optimistic inventory display with pessimistic reservation . Show approximate availability broadly, but use distributed locks when actually reserving items.
📊 Table: Flash Sale System Design Decisions
This decision matrix shows the key architectural choices for high-concurrency inventory systems and their trade-offs.
| Component | Design Choice | Why This Works | Watch Out For |
|---|---|---|---|
| Traffic Entry | Virtual waiting room with queue position | Manages user expectations, prevents thundering herd | Queue abandonment, position accuracy |
| Inventory Check | Cached count with eventual consistency | Handles read load without hitting database | Showing “available” for sold-out items briefly |
| Reservation | Redis DECR with Lua script atomicity | Sub-millisecond atomic inventory decrement | Redis failure modes, persistence guarantees |
| Checkout Timeout | 5-minute reservation with auto-release | Prevents inventory hoarding | Users losing items mid-checkout |
| Payment | Idempotency keys with retry logic | Handles network failures without double-charging | Key generation and storage strategy |
Deep Dive Area: The reservation mechanism deserves special attention. When a user clicks “buy,” you must atomically decrement inventory and create a reservation record. Redis with Lua scripting provides atomic operations faster than traditional databases. The Lua script checks availability and decrements in a single atomic operation, preventing race conditions where two users successfully reserve the last item.
Understanding this level of detail for distributed locking patterns demonstrates you have thought deeply about concurrency challenges that plague production systems.
Case Study 3: Real-Time Chat and Notification Engine
Real-time systems require fundamentally different thinking than request-response architectures. Messages must flow instantly between users. Presence indicators must update in real-time. Notifications must reach users even when they are not actively connected. This pattern applies to chat applications, collaborative editing, live sports updates, and IoT dashboards.
The Core Challenge: Maintaining persistent connections with millions of users while delivering messages with sub-second latency and ensuring no messages are lost even during disconnections.
Key Architectural Components: WebSocket gateway servers maintain persistent connections with clients. A message routing service determines which gateway holds each user’s connection. Message queues buffer messages during brief disconnections. The presence service tracks who is online. Push notification integration handles delivery to offline users.
The Critical Trade-off: Connection statefulness versus horizontal scaling. Stateful connections are efficient but complicate load balancing. Stateless approaches require external state management for every message. The solution uses sticky sessions with graceful connection migration . Users connect to specific gateway servers, but the system can smoothly move connections during scaling events or failures.
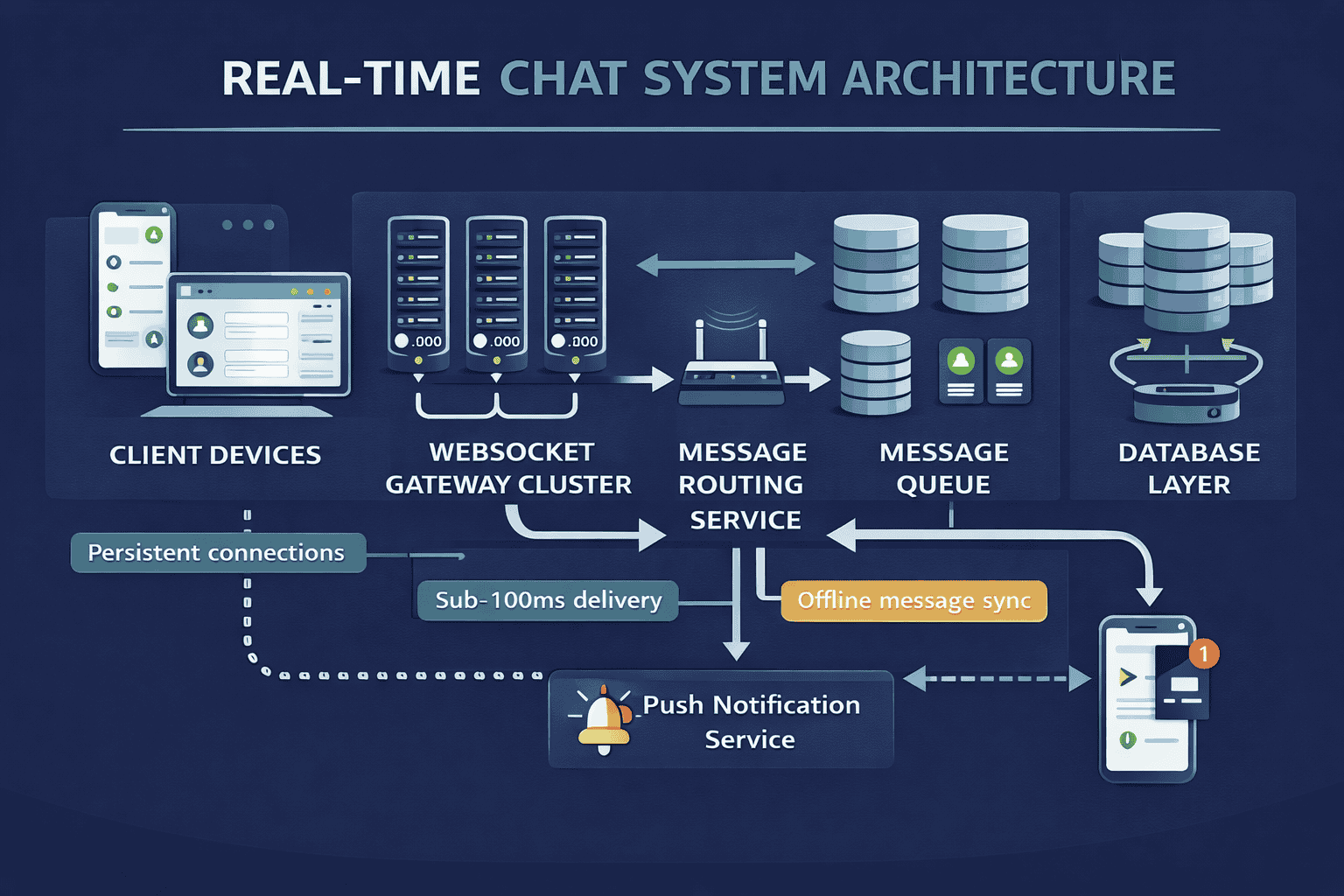
Deep Dive Area: Message ordering and delivery guarantees require careful consideration. In group chats, all participants should see messages in the same order. Vector clocks or Lamport timestamps provide ordering without centralized coordination. For delivery guarantees, implement acknowledgment-based delivery where clients confirm receipt, combined with server-side message persistence for replay during reconnection.
Pattern Recognition Across Case Studies
Notice the recurring themes across these three systems. Each involves managing limited resources under high demand, whether bandwidth, inventory, or connections. Each requires choosing between consistency and availability based on business requirements. Each needs graceful degradation when components fail.
The patterns you learn from one system transfer to others. The CDN strategy from video streaming applies to any content-heavy application. The reservation mechanism from flash sales applies to any limited-resource scenario. The presence tracking from chat applies to any real-time collaboration tool.
When you encounter a new interview question, your first task is pattern matching. Ask yourself which of these archetypes most closely resembles the problem. Then adapt the relevant patterns to the specific requirements. This approach is far more reliable than designing from scratch every time.
📥 Download: Case Study Quick Reference Card
A single-page reference card summarizing the three case studies with their key components, critical trade-offs, and deep dive areas. Perfect for quick review before interviews.
Download PDFThe 8-12 Week Preparation Roadmap: From Foundations to Interview Ready
Knowing what to study is not enough. You need a structured plan that builds skills progressively. This roadmap divides preparation into three phases, each building on the previous. Adjust the timeline based on your starting point and interview dates.
Weeks 1-4: Building the Foundation
The first phase fills knowledge gaps in distributed systems fundamentals. Even experienced developers often have holes in their theoretical understanding. This phase ensures you have the vocabulary and mental models needed for later stages.
Database Internals (Week 1-2): Understand how databases actually work. Study B-tree and LSM-tree storage engines. Learn about write-ahead logging and crash recovery. Explore indexing strategies and query optimization. Know when to choose SQL versus NoSQL and understand the trade-offs deeply.
Networking and Protocols (Week 2-3): Review TCP versus UDP trade-offs. Understand HTTP/2 and HTTP/3 improvements. Learn about WebSockets for real-time communication. Study DNS resolution and CDN routing. Know how load balancers make routing decisions.
Distributed Systems Concepts (Week 3-4): Master CAP theorem and its practical implications. Study consistency models from linearizability to eventual consistency. Learn about consensus protocols like Raft. Understand distributed transactions and the saga pattern. Explore failure detection and leader election.
Weeks 5-8: Framework Practice
The second phase applies your knowledge through structured practice. This is where the 7-step framework becomes automatic. You should complete at least 15-20 practice problems during this phase.
Timed Practice Sessions: Set a 45-minute timer and work through problems end-to-end. Record yourself explaining your design. Review the recording to identify where you stumbled or wasted time. Focus on pacing. Many candidates spend too long on requirements and rush the deep dive.
Mock Interviews: Practice with peers or use professional mock interview services. Real-time feedback from another person reveals blind spots that solo practice misses. Aim for at least 4-6 mock interviews during this phase. The mock interview sessions at GeekMerit.com provide expert feedback from experienced architects who know exactly what top companies evaluate.
Problem Variety: Cover different system types. Practice at least two problems from each category: storage-heavy systems like Dropbox or Google Drive, compute-heavy systems like web crawlers or ML pipelines, real-time systems like chat or live streaming, and transactional systems like payment processors or booking platforms.
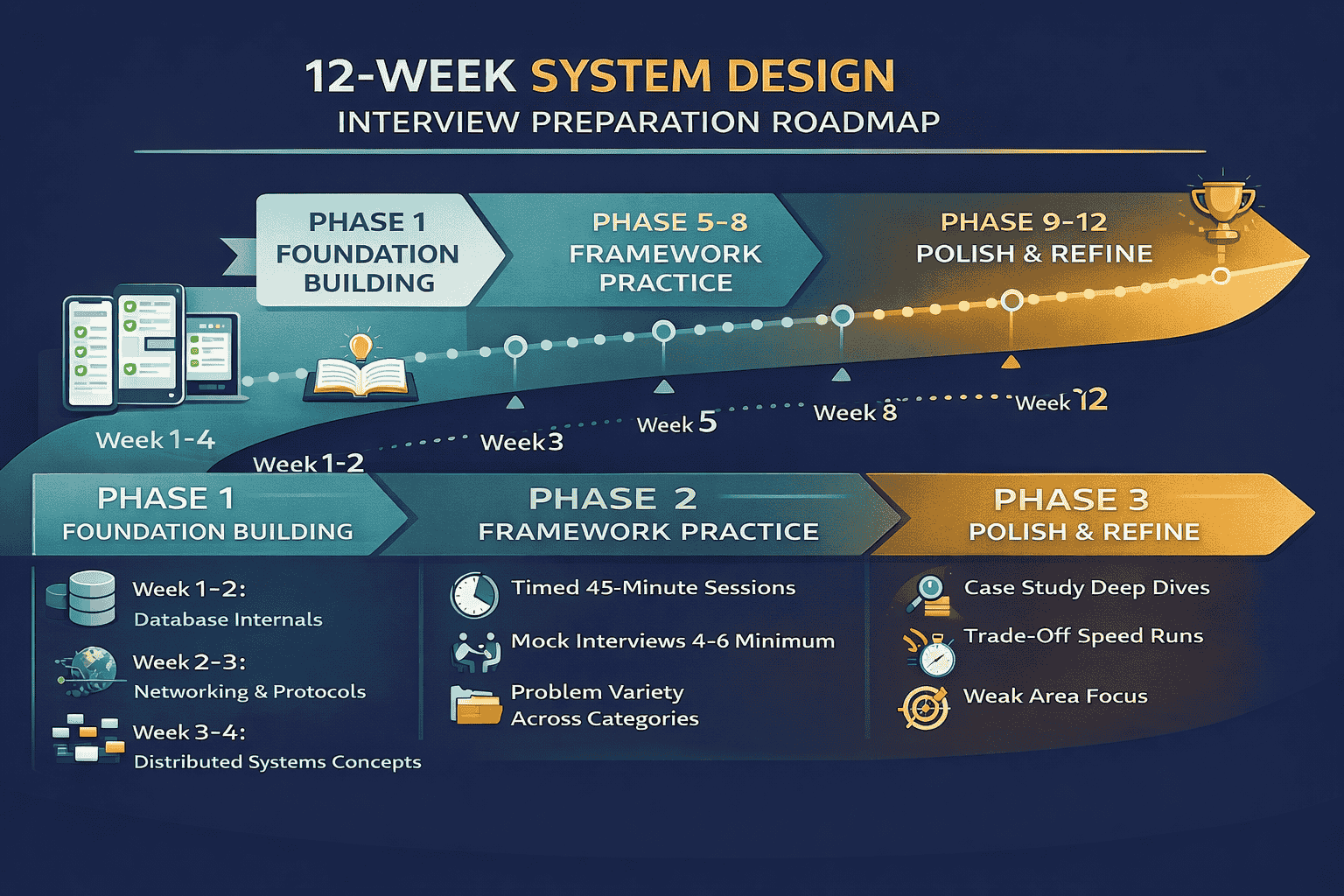
Weeks 9-12: Polish and Refine
The final phase focuses on speed, confidence, and addressing weak areas. You should feel increasingly comfortable with the framework. Now refine your execution.
Case Study Deep Dives: Pick 3-4 systems and study them exhaustively. Read engineering blogs from companies that built them. Understand not just the current architecture but how it evolved. Netflix, Uber, and Slack have published detailed architecture posts. This depth lets you reference real-world examples during interviews.
Trade-off Speed Runs: Practice rapidly articulating trade-offs for common decisions. SQL vs NoSQL. Monolith vs microservices. Push vs pull. Synchronous vs asynchronous. You should be able to give a 30-second summary of each trade-off without hesitation.
Weak Area Focus: Review your mock interview feedback. Identify patterns in your struggles. If you consistently rush requirements gathering, spend extra time on that step. If your capacity estimates are shaky, drill the math. Targeted practice on weaknesses yields more improvement than general review.
Resources & Strategic Next Steps: Tools for Continued Growth
Having a framework is essential. Having the right resources accelerates your progress dramatically. This chapter provides curated tools, checklists, and strategic guidance for taking your preparation to the next level.
The Senior Architect’s Interview Rubric
Before your next practice session or mock interview, use this self-assessment rubric. It mirrors what interviewers evaluate and helps you identify specific areas for improvement.
📊 Table: Senior Architect’s Self-Assessment Rubric
Score yourself from 1-5 on each dimension after every practice session. Track your scores over time to measure improvement and identify persistent weak spots.
| Dimension | 1 (Needs Work) | 3 (Competent) | 5 (Exceptional) |
|---|---|---|---|
| Requirement Gathering | Jumped to solution immediately | Asked basic clarifying questions | Systematically uncovered functional and non-functional requirements |
| Capacity Estimation | Skipped or guessed numbers | Calculated basics but did not connect to decisions | Math directly informed technology and scaling choices |
| High-Level Design | Incomplete or missing key components | All major components present | Clean design with clear data flow and justified choices |
| Deep Dive Quality | Surface-level explanations only | Explained how components work | Discussed internals, failure modes, and alternatives |
| Trade-off Articulation | Single solution without alternatives | Mentioned trade-offs when prompted | Proactively presented options with clear reasoning |
| Communication Flow | Silent drawing or disorganized explanation | Clear explanation but reactive to questions | Led discussion, checked alignment, adapted smoothly |
| Time Management | Ran out of time or rushed major sections | Covered all sections but uneven pacing | Smooth pacing with time for wrap-up and questions |
Essential Reading and Learning Resources
Not all resources are equally valuable. These recommendations focus on materials that directly improve interview performance rather than general computer science education.
For Foundational Concepts: “Designing Data-Intensive Applications” by Martin Kleppmann remains the gold standard. It covers storage engines, replication, partitioning, and distributed systems with depth and clarity. Read chapters 1-9 thoroughly. The later chapters on batch and stream processing are valuable but less frequently tested.
For System Design Patterns: Engineering blogs from major tech companies provide real-world context that textbooks lack. The Netflix Tech Blog, Uber Engineering, and Slack Engineering have published detailed architecture posts. Study how these companies evolved their systems over time, not just the final state.
For Interview-Specific Practice: Generic system design resources often miss the interview context. You need materials that teach both the technical content and the communication patterns expected in 45-minute interviews. The GeekMerit.com curriculum combines 10 comprehensive modules with 200+ practice problems specifically designed for senior .NET developers targeting top-tier companies.
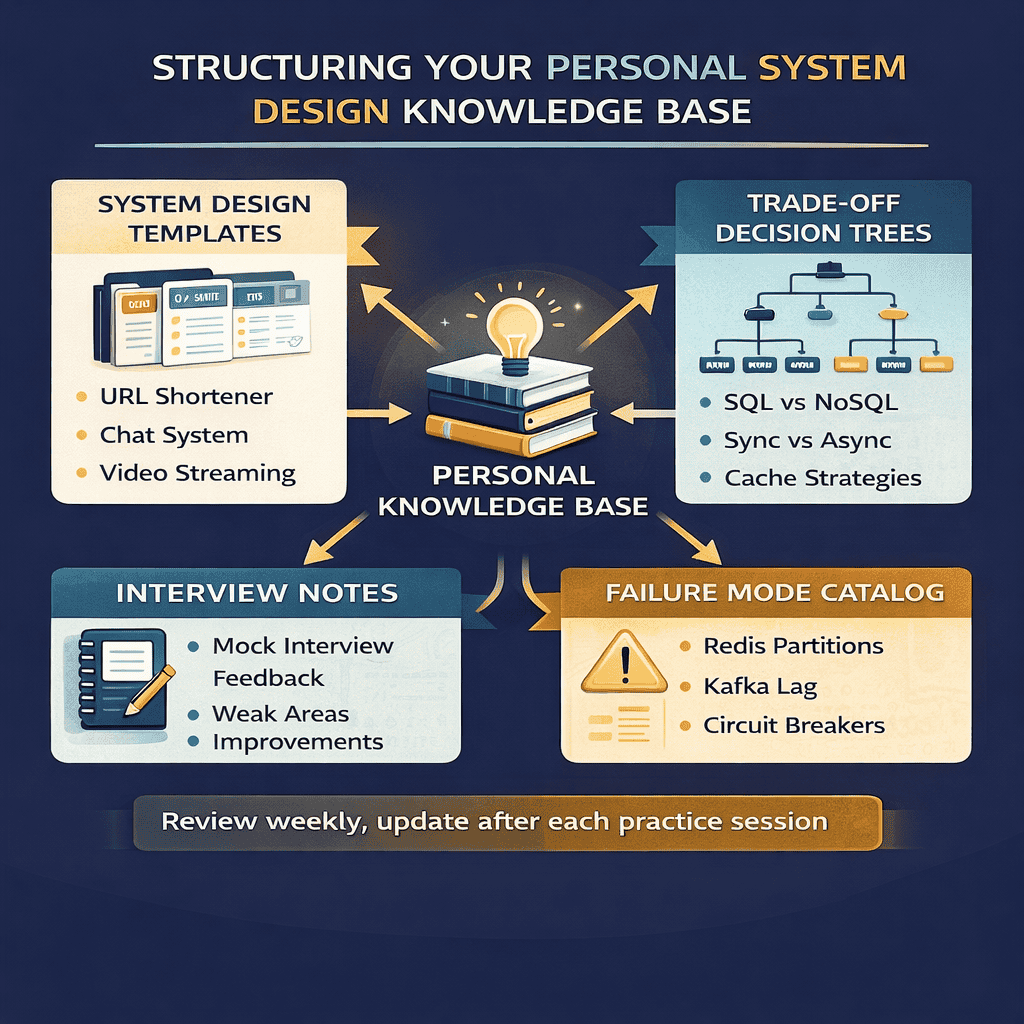
Building Your Personal Knowledge Base
Passive reading does not build interview skills. Active engagement does. Create a personal system design knowledge base that you can review and expand over time.
System Design Template Library: After each practice problem, save your final design as a template. Include the requirements you gathered, the architecture diagram, key trade-offs, and deep dive notes. When you encounter similar problems, you can adapt these templates rather than starting from scratch.
Trade-off Decision Trees: Create decision trees for common choices. When should you choose PostgreSQL versus DynamoDB? When does caching help versus hurt? What factors determine synchronous versus asynchronous processing? These decision trees become mental shortcuts during interviews.
Failure Mode Catalog: Document failure scenarios you learn about. How does Redis behave during network partitions? What happens when Kafka consumers fall behind? How do circuit breakers interact with retry logic? This catalog becomes invaluable when interviewers probe reliability.
The Value of Expert Feedback
Self-study has limits. You cannot see your own blind spots. You cannot accurately assess whether your communication style matches interviewer expectations. You cannot know if your depth is sufficient without someone probing your explanations.
Mock interviews with experienced interviewers provide irreplaceable feedback. They identify patterns in your approach that hold you back. They calibrate your expectations for what “good” looks like at L6+ levels. They simulate the pressure of real interviews so you build comfort with the format.
The difference between candidates who pass and candidates who fail often comes down to preparation quality, not raw ability. Structured coaching accelerates improvement dramatically compared to unguided practice. If you are serious about landing a senior role at a top company, investing in expert feedback is one of the highest-return decisions you can make.
Structured Coaching: The Accelerated Path
For developers who want the fastest path to interview readiness, structured coaching programs provide comprehensive support. The right program combines curriculum, practice, and feedback into an integrated experience.
What to look for in a coaching program: Content specifically designed for your experience level and target companies. Practice problems that mirror actual interview formats. Personalized feedback from engineers who have conducted interviews at top companies. A community of peers at similar career stages for mutual support and practice.
The GeekMerit.com coaching programs offer three tiers designed for different learning styles. The Self-Paced option at $197 provides all course materials and practice problems for independent learners. The Guided option at $397 adds live coaching sessions and personalized feedback on your designs. The Bootcamp option at $697 includes intensive 1-on-1 coaching, live mock interviews, and a personalized study plan for maximum support.
📊 Table: Choosing the Right Preparation Path
Match your preparation approach to your timeline, learning style, and interview goals.
| Factor | Self-Study | Guided Coaching | Intensive Bootcamp |
|---|---|---|---|
| Timeline | 3-6 months | 2-3 months | 6-10 weeks |
| Best For | Self-motivated learners with flexible schedules | Developers wanting structure with some flexibility | Developers with upcoming interviews needing fast results |
| Feedback Quality | Self-assessment and peer review | Expert feedback on specific designs | Comprehensive feedback with personalized improvement plan |
| Investment | Time-intensive, lower cost | Balanced time and cost | Higher cost, fastest results |
| Success Rate | Variable based on discipline | Higher with structured accountability | Highest with intensive support |
Your Path to System Design Interview Success
You now have everything you need to transform your system design interview performance. The framework provides structure. The case studies provide patterns. The roadmap provides direction. What remains is execution.
The Transformation Ahead
Remember where we started. The “Senior Gap” that causes experienced developers to fail interviews despite years of production experience. The four pillars that interviewers actually evaluate. The 7-step framework that ensures you cover all dimensions within your 45 minutes.
You learned the advanced concepts that differentiate strong candidates. Consistency models. Edge cases like hot keys and thundering herds. The wisdom to know when simpler architectures are better than distributed complexity.
You studied three case studies representing the most common interview patterns. Video streaming for content delivery. Flash sales for high concurrency. Real-time chat for persistent connections. These patterns transfer to countless other problems you will encounter.
You have a 12-week roadmap that builds skills progressively. Foundations first. Framework practice second. Polish and refinement third. This structure prevents the scattered approach that undermines most self-study efforts.
Taking Action Today
Knowledge without action is worthless. Here are your immediate next steps based on your current situation.
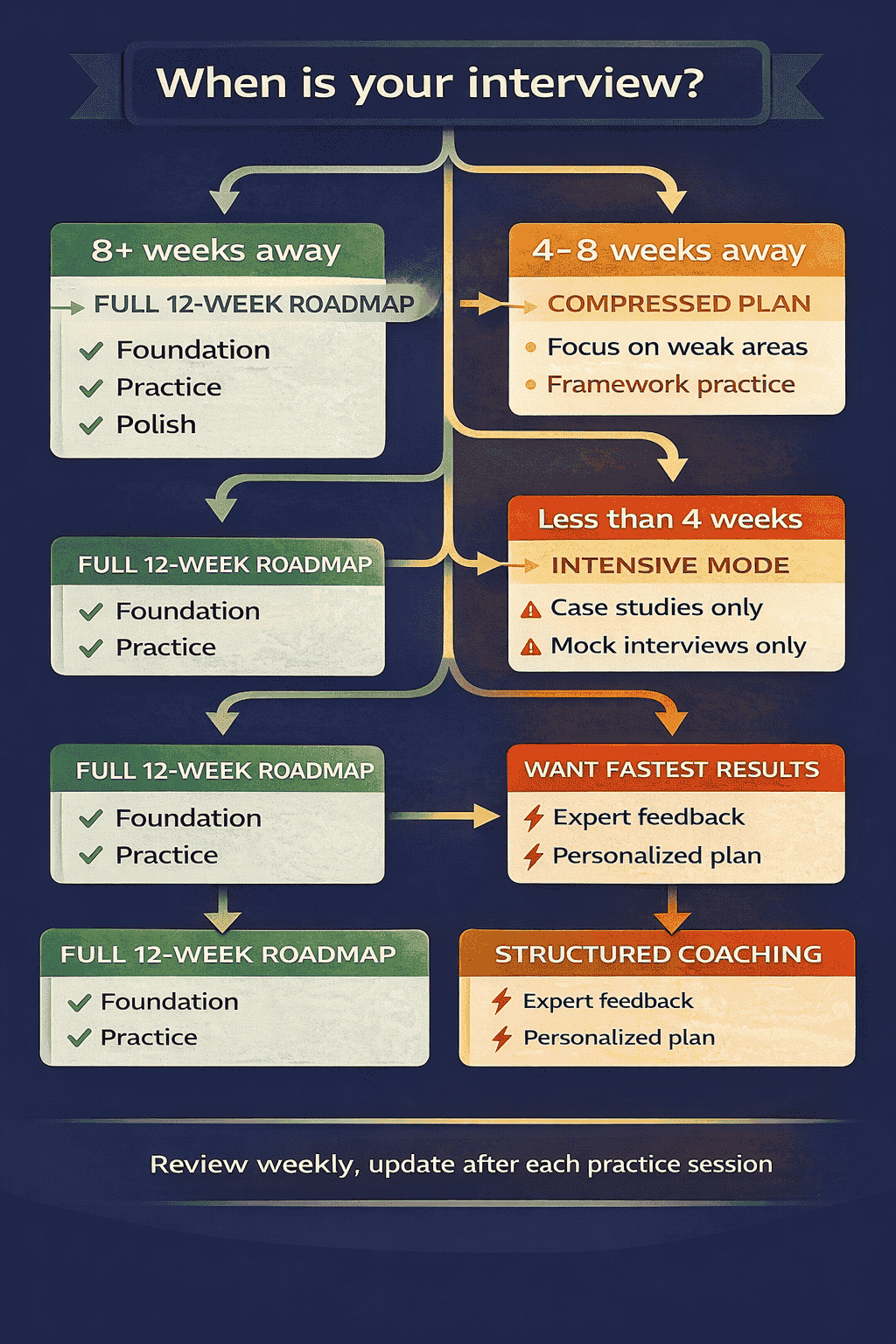
If your interview is more than 8 weeks away: Follow the complete 12-week roadmap. Start with the foundation phase. Build your knowledge base systematically. You have time to do this right.
If your interview is 4-8 weeks away: Compress the foundation phase into two weeks of intensive study. Focus on the concepts you know are weak. Spend most of your time on framework practice and mock interviews.
If your interview is less than 4 weeks away: Focus entirely on framework practice and the three case studies. Do at least 10 timed practice problems. Get at least 2-3 mock interviews with feedback. At this point, building new knowledge is less valuable than refining what you already know.
If you want accelerated results: Consider the GeekMerit.com course designed specifically for senior .NET developers. With 48 video lessons, 200+ practice problems, and optional live coaching, it provides the most efficient path from where you are to interview-ready.
The Mindset for Success
Finally, remember that system design interviews are learnable skills. They are not measures of innate intelligence. They are not tests of whether you have built the exact system being asked about. They are demonstrations of how you think through complex problems.
Every candidate who passes these interviews did the work. They studied the concepts. They practiced the framework. They refined their communication. They got feedback and improved. There is no shortcut, but there is also no mystery. The path is clear.
You have the experience. You have the technical foundation. Now you have the framework and the roadmap. The only remaining variable is your commitment to preparation. Make that commitment today, and your next system design interview will be the one that changes your career.
Frequently Asked Questions
How long should I prepare for a system design interview?
Most senior developers need 8-12 weeks of focused preparation to perform well in system design interviews. If you have a strong distributed systems background, you might compress this to 4-6 weeks. If you are coming from a more specialized role without broad architecture exposure, plan for the full 12 weeks. The key is consistent daily practice rather than cramming, as system design skills require time to internalize.
What is the biggest mistake senior developers make in system design interviews?
The most common mistake is jumping directly to drawing architecture diagrams without first clarifying requirements. Interviewers deliberately provide vague prompts to see how you handle ambiguity. When you start designing before understanding the constraints, you often build the wrong system. Spend the first 5 minutes asking targeted questions about functional requirements, scale expectations, and consistency needs before touching the whiteboard.
Do I need to memorize specific systems like how Netflix or Uber work?
You do not need to memorize exact architectures, but you should understand the patterns these systems use. Interviewers are not testing whether you read a specific blog post. They want to see whether you can reason about trade-offs and apply appropriate patterns to new problems. Studying real systems helps you build pattern recognition, but the goal is understanding principles rather than memorizing implementations.
How important is coding in a system design interview?
Most system design interviews do not require writing code. The focus is on architecture, trade-offs, and communication. However, you should be able to write pseudocode for critical algorithms when relevant. For example, if you propose consistent hashing, you should be able to sketch the hash ring logic. Some companies combine system design with coding rounds, so check with your recruiter about the specific format.
Should I use specific technologies like AWS services or keep designs technology-agnostic?
Use specific technologies when they add clarity to your design, but always explain why you chose them. Saying “we will use DynamoDB for its single-digit millisecond latency and automatic scaling” demonstrates knowledge. Saying “we will use DynamoDB because it is popular” does not. The key is connecting technology choices to requirements. If you are interviewing at a company that uses specific cloud providers, knowing their services well can be an advantage.
How do I handle it when the interviewer asks about something I do not know?
Honesty is always the best approach. Say something like “I have not worked with that specific technology, but based on similar systems I have used, I would expect it to behave like this.” Then reason through the problem using first principles. Interviewers appreciate candidates who can think through unfamiliar territory rather than pretending to know everything. Admitting gaps while demonstrating strong reasoning often scores better than confident but incorrect answers.
Citations
- https://dataintensive.net/
- https://netflixtechblog.com/
- https://eng.uber.com/
- https://aws.amazon.com/architecture/
- https://cloud.google.com/architecture
- https://learn.microsoft.com/en-us/azure/architecture/
- https://martinfowler.com/articles/patterns-of-distributed-systems/
- https://research.google/pubs/pub51563/
- https://www.allthingsdistributed.com/
Content Integrity Note
This guide was written with AI assistance and then edited, fact-checked, and aligned to expert-approved teaching standards by Andrew Williams . Andrew has over 10 years of experience coaching software developers through technical interviews at top-tier companies including FAANG and leading enterprise organizations. His background includes conducting 500+ mock system design interviews and helping engineers successfully transition into senior, staff, and principal roles. Technical content regarding distributed systems, architecture patterns, and interview evaluation criteria is sourced from industry-standard references including engineering blogs from Netflix, Uber, and Slack, cloud provider architecture documentation from AWS, Google Cloud, and Microsoft Azure, and authoritative texts on distributed systems design.

