Design Rate Limiter System Design: The Complete Guide for Interviews & Real-World Systems
When you’re asked to design rate limiter system design in a technical interview, most candidates freeze . They know rate limiting protects APIs from abuse, but translating that knowledge into a complete system design feels overwhelming.
Here’s the truth: interviewers aren’t testing whether you’ve memorized token bucket algorithms. They’re evaluating how you think.
If you’re mainly preparing from playlists and scattered notes, compare paths: System Design Coaching vs YouTube for Interview Prep.
Can you clarify vague requirements? Do you understand trade-offs between accuracy and performance? Can you scale a solution from thousands to millions of requests? This guide walks you through designing a rate limiter exactly as strong candidates approach it in real interviews —step by step, decision by decision.
Last updated: Feb. 2026

Table of Contents
- 1. The Interview Context: What Interviewers Actually Test
- 2. Requirement Clarification (Most Candidates Skip This)
- 3. High-Level Design Overview
- 4. API Design for Rate Limiting
- 5. Algorithm Selection Through Real Scenarios
- 6. Data Storage & Schema Design
- 7. Scaling the Rate Limiter (The Real Test)
- 8. Trade-Offs & Decision Justification
- 9. Your Path to Rate Limiter Mastery
- 10. FAQs
Contents
The Interview Context: What Interviewers Actually Test
You walk into the interview room. The interviewer writes on the whiteboard: “Design a rate limiter for a public API used by millions of clients.”
Your mind races. Redis? Token buckets? Distributed systems?
Here’s what most candidates miss: the interviewer doesn’t care if you know the “right” algorithm. They’re evaluating something deeper—your ability to navigate ambiguity, communicate technical decisions, and build systems incrementally under pressure.
What Strong Candidates Do Differently
Senior engineers who ace system design interviews follow a specific pattern. They don’t jump straight into implementation.
Instead, they pause. They ask clarifying questions . They sketch high-level architectures before diving into details. They acknowledge trade-offs openly rather than claiming one “perfect” solution exists.
This is structured thinking made visible. When an interviewer asks you to design a rate limiter, they’re testing whether you can transform vague requirements into working systems—the exact skill you’ll need when designing real production infrastructure.
The First Five Minutes Matter Most
Most interview failures happen in the first five minutes. Candidates either freeze in silence or start building the wrong thing confidently.
Strong candidates use those critical minutes to clarify the problem space. Is this rate limiting per user, per IP, or per API key? Are bursts allowed? What happens when limits are exceeded? Should the system prioritize accuracy or throughput?
These questions aren’t stalling tactics. They’re demonstrations of professional engineering judgment. Every answer shapes your design fundamentally—choosing between algorithms, storage systems, and architectural patterns.
📊 Table: Interview Evaluation Criteria for Rate Limiter Design
Interviewers assess your rate limiter design across multiple dimensions. Understanding these evaluation criteria helps you structure your approach during the interview.
| Evaluation Area | What Interviewers Look For | Red Flags |
|---|---|---|
| Requirement Gathering | Asks targeted questions about scale, accuracy needs, failure behavior | Jumps to implementation without clarifying constraints |
| System Thinking | Starts with high-level design, then drills into components | Focuses on single component (algorithm) without broader context |
| Trade-Off Analysis | Articulates pros/cons of design choices, acknowledges limitations | Claims design is “perfect” or dismisses alternative approaches |
| Scalability Awareness | Discusses single-node vs distributed, failure scenarios, bottlenecks | Designs for small scale without considering growth path |
| Communication | Explains reasoning clearly, invites feedback, adapts to hints | Works silently, ignores interviewer questions or guidance |
Common Mistakes in the Opening Phase
The biggest mistake? Over-engineering too early. Candidates mention distributed consensus, advanced data structures, and complex failure recovery before establishing basic requirements.
Another pitfall: treating the interview like a code challenge. Rate limiter design isn’t about implementing perfect algorithms—it’s about designing systems that balance competing constraints.
Avoid buzzword bingo. Saying “we’ll use Redis ” without explaining why, or mentioning “token bucket” without connecting it to actual traffic patterns, signals surface-level understanding. Interviewers want to see your thinking process, not your vocabulary.
What Success Looks Like
A strong interview sounds like a professional design discussion. You’re thinking aloud, weighing options, and building solutions incrementally.
You acknowledge when you’re making assumptions. You explain why you’re choosing simplicity over accuracy, or vice versa. You describe how your design would evolve as requirements change.
This consultative approach demonstrates senior-level judgment. You’re not just answering the question—you’re showing how you’d approach ambiguous problems in real work environments where perfect information never exists.
Requirement Clarification (Most Candidates Skip This)
The interviewer has given you a deceptively simple prompt: “Design a rate limiter.” Most candidates immediately start sketching Redis clusters or explaining token bucket math.
This is a trap.
Every design decision you make—algorithm choice, storage system, failure handling—flows directly from requirements you haven’t clarified yet. Strong candidates spend 10-15 minutes in this phase, and it’s time well invested.
The Essential Questions Framework
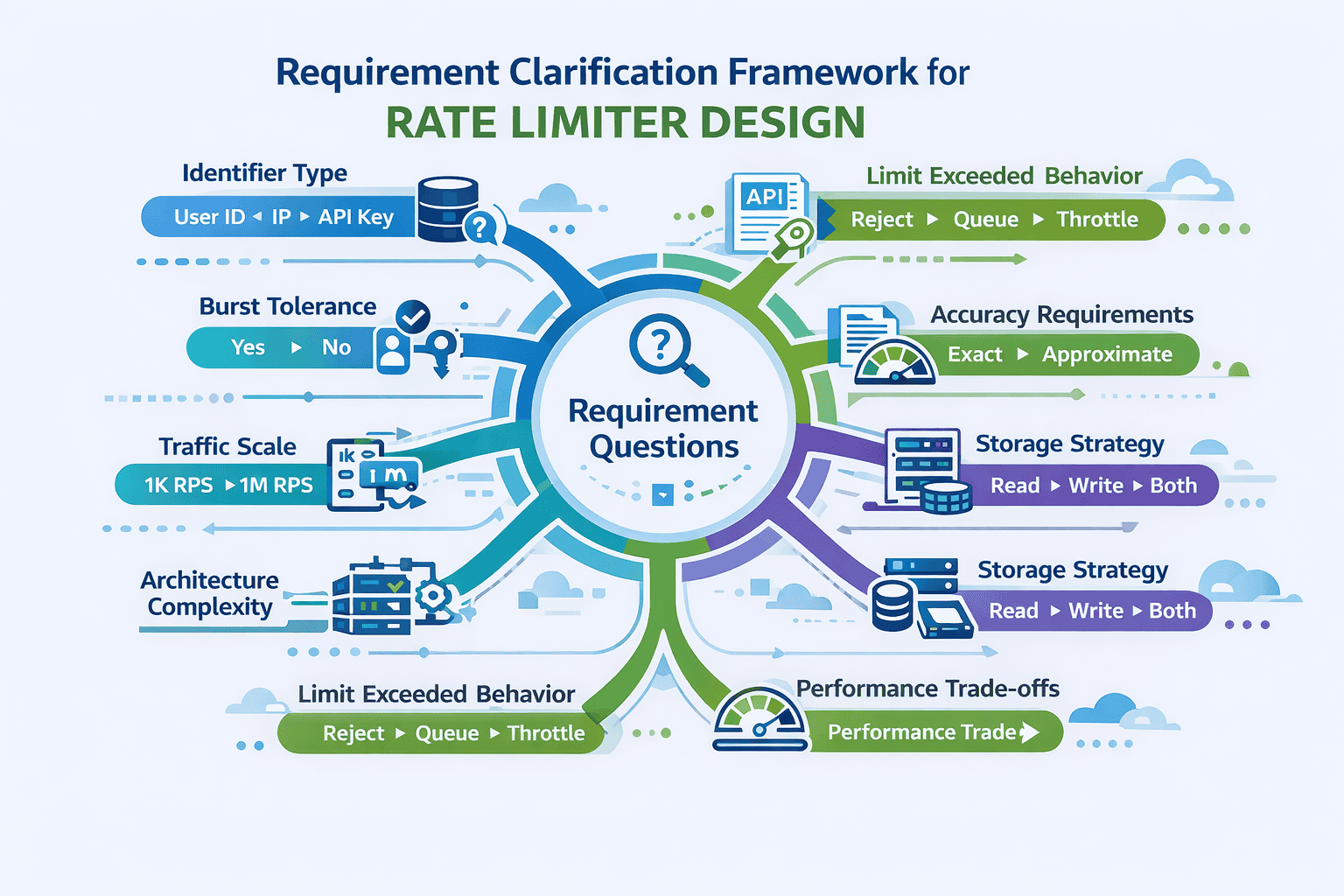
Let’s walk through the questions that separate junior from senior-level thinking. Each question reveals hidden complexity and validates your engineering judgment.
Question 1: What identifier determines the rate limit?
This single question shapes your entire architecture. Rate limiting by user ID requires authentication context. Limiting by IP address handles anonymous traffic but struggles with NAT and proxies. API key limiting supports programmatic access but needs key distribution infrastructure.
The answer determines your data model, key structure, and integration points. Don’t assume—ask.
Question 2: Are traffic bursts acceptable?
This question reveals whether you understand traffic patterns. Real-world API usage isn’t smooth—clients retry failed requests, batch operations create spikes, and legitimate workflows generate bursts.
If bursts are acceptable, you’ll favor token bucket or leaky bucket algorithms. If strict rate enforcement matters more, fixed or sliding windows work better. Each choice has performance implications you’ll discuss later.
Scope and Scale Questions
Question 3: What’s the expected scale?
Are we handling 1,000 requests per second or 10 million? This determines whether you need distributed storage, what your latency budget looks like, and whether eventual consistency is acceptable.
Small-scale systems can use simple in-memory counters. Large-scale systems need distributed architectures with caching layers. Getting this wrong means designing a Ferrari when the interviewer wanted a bicycle—or vice versa.
Question 4: What happens when limits are exceeded?
Should the system reject requests immediately? Queue them? Apply back-pressure? The answer affects your API contract, client experience, and error handling strategy.
Different behaviors require different architectures. Hard rejections are simple. Queueing adds state management complexity. Discussing these options shows you’re thinking about user experience, not just technical implementation.
Technical Constraint Questions
Question 5: How accurate must the limiting be?
Perfect accuracy is expensive. Approximate limiting is fast. The difference between “exactly 1000 requests per hour” and “roughly 1000 requests per hour” determines whether you need strong consistency or can use eventual consistency with local caches.
This question signals you understand distributed systems fundamentals. In high-scale environments, perfect accuracy across data centers is nearly impossible without sacrificing performance. Admitting this trade-off demonstrates maturity.
Question 6: Are we limiting reads, writes, or both?
Writes are expensive. Reads can be cached. If you’re only limiting write operations, your rate limiter can be simpler because the traffic pattern is more predictable.
Read-heavy APIs with occasional writes might use different limiting strategies per operation type. This question shows you’re thinking about real-world workload characteristics, not just abstract algorithms.
How to Ask These Questions
Don’t interrogate your interviewer. Frame questions as design explorations: “To choose the right algorithm, I need to understand whether burst traffic is acceptable. Should I optimize for smooth traffic distribution or allow legitimate bursts?”
This phrasing shows you’re connecting questions to design decisions. You’re not asking random questions—you’re gathering information that will shape specific architectural choices you’ll explain later.
Take notes. Write down the answers. Reference them when explaining design decisions. This creates a narrative thread through your interview: “Earlier you mentioned burst traffic is acceptable, so I’m choosing token bucket over fixed window because…”
High-Level Design Overview
You’ve clarified requirements. Now the interviewer expects you to sketch a high-level architecture before diving into implementation details.
This is where many candidates stumble. They either draw overly complex distributed systems or oversimplify to the point of uselessness.
Strong candidates start simple, then evolve the design based on constraints. Let’s walk through this progression exactly as it happens in successful interviews.
The Request Lifecycle
Every rate limiter sits somewhere in your request path. Understanding where it lives determines everything else about your design.
The basic flow looks like this: Client sends request → Request hits your infrastructure → Rate limiter checks allowance → Request either proceeds to your service or gets rejected.
But where exactly does that check happen? At the API gateway? Inside each service? In a dedicated middleware layer? Each choice has implications for latency, complexity, and failure handling.
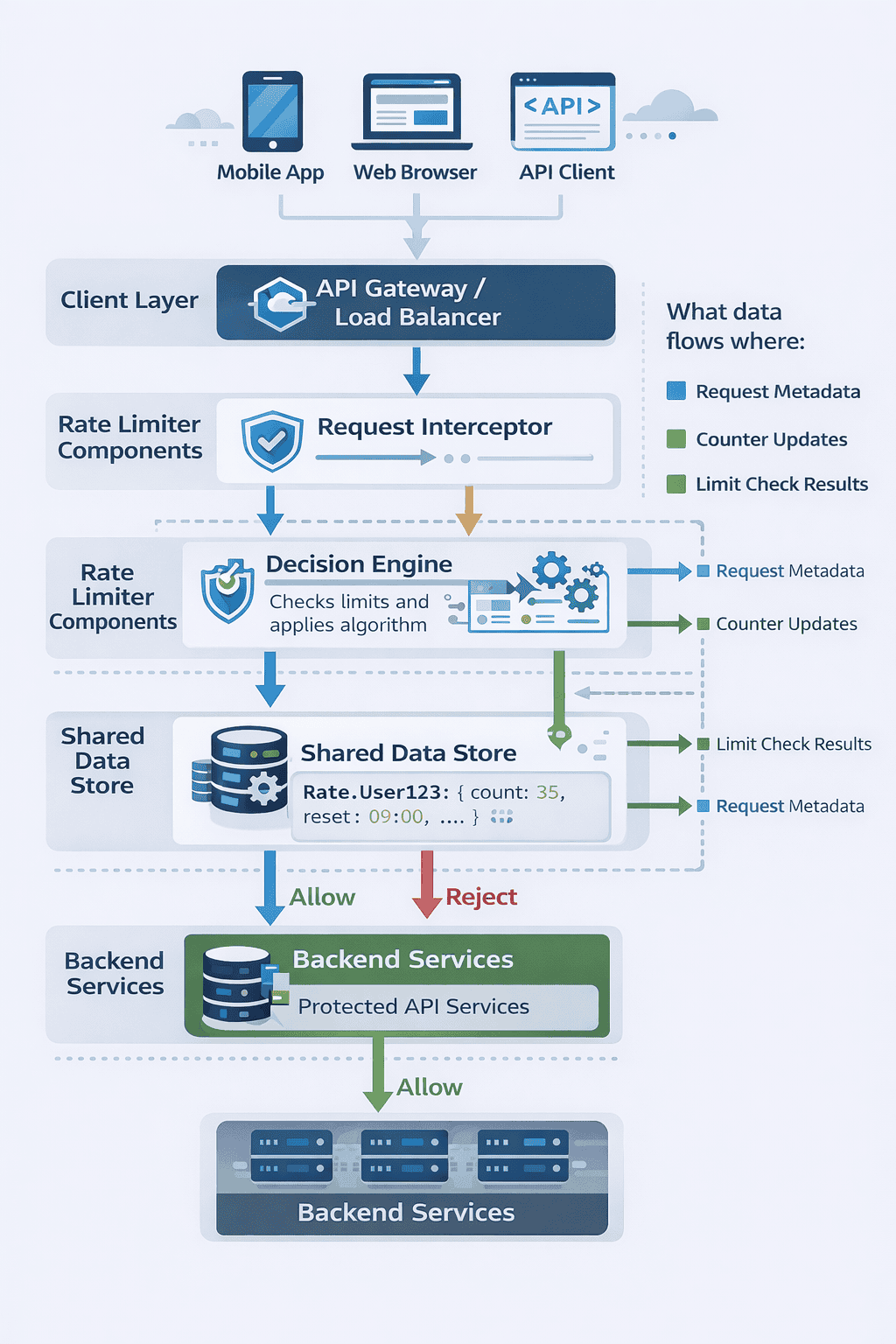
Component-Level Architecture
At minimum, your rate limiter needs three components working together. First, a decision engine that determines whether to allow or reject requests. Second, a data store tracking request counts and timestamps. Third, integration points where the limiter intercepts requests.
Start by drawing these three boxes on the whiteboard. Label them clearly. Explain what each component does before worrying about how it does it.
The decision engine contains your rate limiting algorithm—we’ll choose the specific algorithm later based on requirements. The data store holds state about request counts per identifier. The integration layer connects your limiter to existing infrastructure.
What Data Flows Through the System
Understanding data flow prevents design mistakes. When a request arrives, what information does your rate limiter need to make a decision?
At minimum: an identifier (user ID, IP address, API key), a timestamp (when did this request happen), and context about which resource is being accessed (different endpoints might have different limits).
The decision engine takes this input, queries the data store for current state, applies your algorithm, updates the state, and returns a binary decision: allow or reject.
If allowed, the request continues to your backend services. If rejected, you return an HTTP 429 status code with headers indicating when the client can retry. These details matter—they’re part of the API contract you’ll design next.
Progressive Refinement: Starting Simple
Here’s how strong candidates evolve their design during the interview. You start with the simplest possible architecture that could work.
Version 1 might be: single server, in-memory counter, one rate limit applied globally. This handles maybe 1,000 requests per second. You draw this in 30 seconds, then say “This works for small scale. Let me evolve it based on our requirements.”
The interviewer nods. You’re showing you can start simple and add complexity only when needed—a critical senior engineering skill.
Scaling to Multiple Servers
Now you evolve the design. “If we’re handling millions of requests across multiple servers, in-memory counters won’t work—each server would have different counts.”
You add a shared data store. Maybe Redis for fast access. Suddenly your simple architecture becomes distributed, and you need to discuss consistency, latency, and failure scenarios.
This progression feels natural because you’re responding to specific constraints. You’re not dumping a complete distributed system on the whiteboard—you’re building it piece by piece with clear reasoning at each step.
Where the Rate Limiter Lives
One critical decision: should rate limiting happen at the API gateway or inside your services?
Gateway-level limiting protects your entire infrastructure. It’s centralized and easier to manage. But it can’t make service-specific decisions—it doesn’t know which requests are expensive versus cheap.
Service-level limiting allows fine-grained control. You can apply different limits based on operation cost. But now you’re implementing rate limiting logic in multiple places, increasing complexity.
There’s no perfect answer. Strong candidates acknowledge both approaches, explain trade-offs, and choose based on the requirements you clarified earlier. If you need simple global limits, gateway works. If you need operation-specific limits, service-level makes sense.
Handling the Happy Path
Before discussing failures, describe normal operation. “When a request arrives, the gateway extracts the client identifier and current timestamp. It queries Redis with key `ratelimit:user:12345` to get the current request count and window start time.”
Walk through the logic: “If the count is below the limit and we’re still in the current time window, increment the counter, allow the request, and return. If we’ve exceeded the limit, reject with HTTP 429 and include a `Retry-After` header.”
This verbal walkthrough demonstrates you can translate architecture diagrams into actual system behavior. You’re not just drawing boxes—you’re describing how data moves and decisions get made.
API Design for Rate Limiting
Your rate limiter isn’t a black box. It’s part of an API contract between your system and clients. How you communicate limits and rejections affects user experience and client behavior.
Most candidates skip API design entirely or mention it in passing. This is a mistake. The API surface reveals whether you’ve thought through the client developer’s experience.
Request-Side Interface
What does the rate limiter need from each incoming request? At minimum, it needs to identify who’s making the request and what they’re requesting.
For user-based limiting, you need an authenticated user ID. For IP-based limiting, you extract the client IP from request headers. For API key limiting, you read the key from an Authorization header or query parameter.
The endpoint being accessed matters too. Your limiter might allow 1,000 read requests per hour but only 100 write requests. This means your API contract includes both the identifier and the operation type.
Response Headers: The Often-Forgotten Detail
When you accept a request, you should tell clients how close they are to their limits. This prevents surprise rejections and allows clients to implement smart retry logic.
Standard practice includes three response headers for every successful request:
X-RateLimit-Limit: The maximum number of requests allowed in the current window. Example: 1000.
X-RateLimit-Remaining: How many requests the client can still make. Example: 742.
X-RateLimit-Reset: Unix timestamp when the current window resets. Example: 1640995200.
These headers transform rate limiting from a mysterious black box into a transparent system. Client developers can build adaptive behavior—slowing down requests as they approach limits, scheduling expensive operations for after resets.
📊 Table: Standard Rate Limit Response Headers
These HTTP headers communicate rate limit state to clients, enabling smart retry logic and preventing surprise rejections. Following these conventions makes your API predictable and developer-friendly.
| Header Name | Purpose | Example Value | When Included |
|---|---|---|---|
| X-RateLimit-Limit | Maximum requests allowed in current window | 1000 | Every successful response |
| X-RateLimit-Remaining | Requests remaining before hitting limit | 742 | Every successful response |
| X-RateLimit-Reset | Unix timestamp when window resets | 1640995200 | Every successful response |
| Retry-After | Seconds until client can retry | 3600 | Only when request is rejected (429) |
| X-RateLimit-Policy | Human-readable limit description | “1000 per hour” | Optional, helpful for debugging |
Rejection Response Design
When you reject a request, the HTTP status code is obvious: 429 Too Many Requests. But the response body and headers matter just as much.
At minimum, include a Retry-After header telling clients when they can retry. Express this in seconds from now: “Retry-After: 3600” means try again in one hour.
The response body should explain what happened in human-readable terms. Include the limit that was exceeded, the current request count, and when the window resets. Good error messages prevent support tickets.
Example response body:
{
"error": "rate_limit_exceeded",
"message": "You have exceeded the rate limit of 1000 requests per hour",
"limit": 1000,
"current": 1001,
"reset_at": "2024-02-06T15:00:00Z",
"retry_after_seconds": 3600
}
Multiple Limit Tiers
Real-world systems often have multiple simultaneous limits: 10 requests per second AND 1000 requests per hour AND 10,000 requests per day.
Your API contract needs to handle this complexity. When rejecting a request, which limit should you report? The one that was actually exceeded. If someone hits the per-second limit, don’t confuse them by talking about hourly limits.
For successful requests, you might include multiple sets of headers—one for each limit tier. Or you might only report the most restrictive limit to keep responses simple. There’s no universal right answer, but discussing it shows depth.
Error Codes and Client Behavior
Different types of limit violations might warrant different error codes. Exceeding a per-user limit is a 429. But what if the entire system is overloaded and you’re rejecting all requests?
Some systems use 503 Service Unavailable for system-wide overload versus 429 for individual limits. This distinction helps clients implement different retry strategies—back off longer for 503, retry after the specific window for 429.
These nuances demonstrate you’re thinking beyond the basic case. You’re designing for real-world scenarios where systems get overloaded, clients misbehave, and edge cases matter.
Algorithm Selection Through Real Scenarios
Now comes the moment most candidates anticipate: choosing a rate limiting algorithm. But here’s the trap—memorizing algorithm definitions doesn’t help if you can’t explain when to use each one.
Strong candidates introduce algorithms through scenarios, not definitions. They show how traffic patterns and requirements naturally point toward specific algorithmic choices.
Let’s walk through the four main algorithms exactly as they emerge from real requirements.
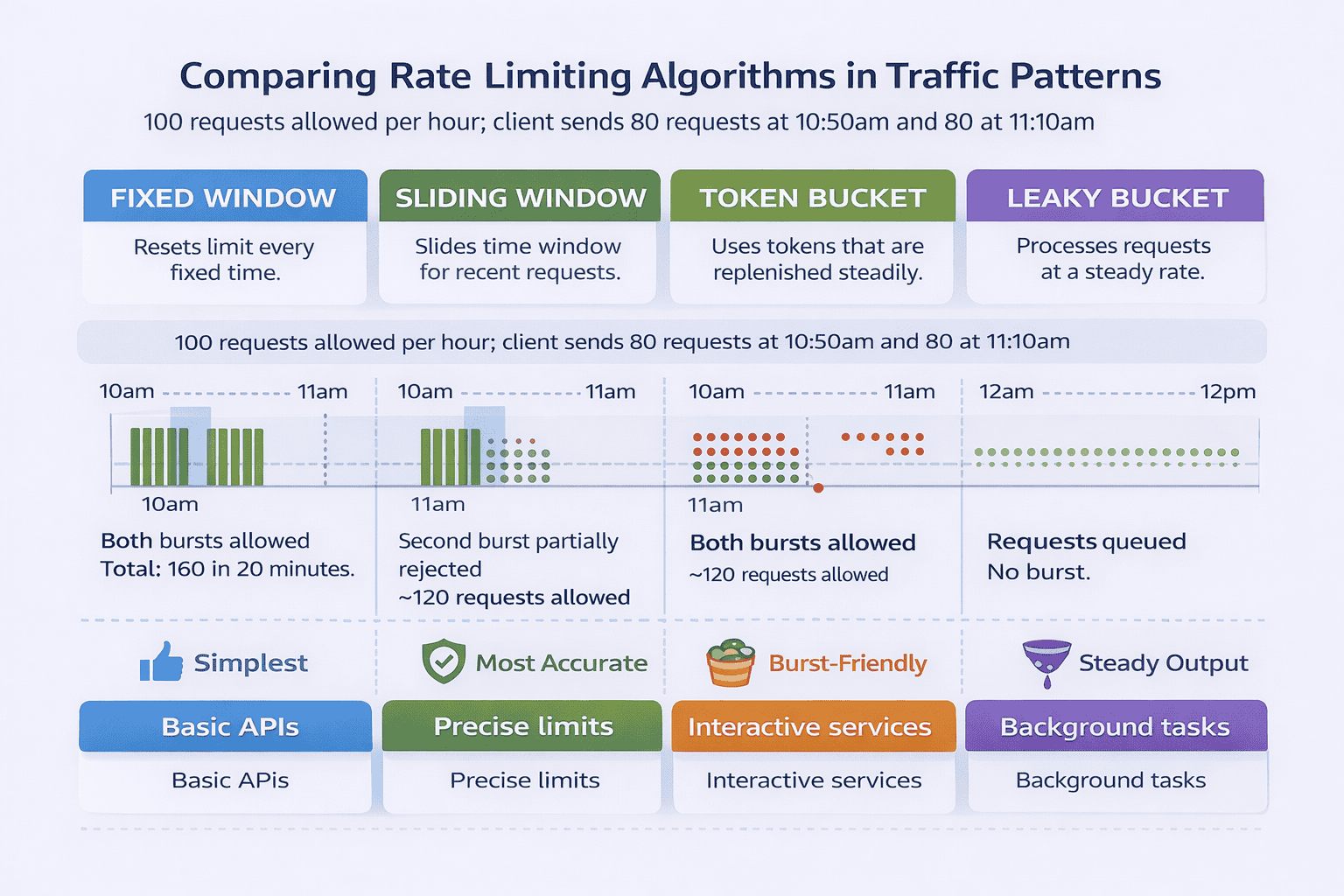
Fixed Window: When Simplicity Matters Most
Imagine your requirement is straightforward: limit each API key to 1,000 requests per hour. No burst tolerance required. You want something simple to implement and explain.
Fixed window fits perfectly. You divide time into discrete one-hour windows. At the start of each window, the counter resets to zero. Each request increments the counter. When the counter hits 1,000, you reject requests until the window resets.
Implementation is trivial: store a counter with a timestamp marking the window start. On each request, check if you’re in a new window. If yes, reset the counter. If no, increment and compare against the limit.
The weakness? Boundary exploitation. A client could make 1,000 requests at 10:59am and another 1,000 at 11:01am—getting 2,000 requests in two minutes despite an hourly limit. For many use cases, this edge case doesn’t matter. For high-security APIs, it’s unacceptable.
Sliding Window Log: When Accuracy is Critical
Your interviewer pushes back: “What if boundary exploitation is a problem? We need strict enforcement.”
You evolve to sliding window log. Instead of discrete windows, you track the exact timestamp of each request. When a new request arrives, you query all requests from the past hour and count them.
If the count is below 1,000, you accept the request and store its timestamp. If above, you reject. This approach eliminates boundary issues—limits are enforced over any 60-minute period, not just clock-hour boundaries.
The trade-off is obvious: memory usage. For high-traffic APIs, storing individual timestamps for every request becomes expensive. A user making 1,000 requests per hour needs 1,000 timestamp entries in your data store.
Sliding Window Counter: The Practical Compromise
Most production systems use a hybrid approach: sliding window counter. It approximates sliding window log accuracy without the memory overhead.
Here’s how it works. You maintain two counters: one for the previous window and one for the current window. When a request arrives partway through the current window, you estimate the rate using a weighted formula.
For example, if you’re 30 minutes into the current hour, you weight the previous hour’s count at 50% and the current hour’s count at 100%. This approximation is usually accurate enough while using constant memory—just two counters regardless of request volume.
The formula looks like:
rate = current_window_count + previous_window_count * (1 - elapsed_time_percentage)
This approach appears in production systems at companies like Stripe and Twitter because it balances accuracy, performance, and simplicity beautifully.
Token Bucket: When Bursts are Legitimate
Your requirements change: “We need to allow occasional bursts. A client might be idle for 30 minutes, then legitimately send 500 requests in one minute during a batch operation.”
Token bucket handles this elegantly. Imagine a bucket that holds tokens. Tokens are added at a constant rate—say, 100 tokens per hour. Each request consumes one token. If tokens are available, the request proceeds. If not, it’s rejected.
The bucket has a maximum capacity. If you’re not making requests, tokens accumulate up to that cap. This allows bursts—a client can “save up” tokens during quiet periods and spend them quickly when needed.
Implementation requires two values: the token count and the last refill timestamp. On each request, calculate how many tokens to add based on elapsed time, add them (capped at bucket capacity), then try to consume one token.
Token bucket works well for APIs where legitimate workflows create bursts, like data import operations or batch processing jobs.
Leaky Bucket: When Steady Output Matters
A different requirement emerges: “We need to protect our downstream service, which can only handle requests at a steady rate. Bursts cause problems even if the hourly total is acceptable.”
Enter leaky bucket. Requests enter a queue (the bucket). They “leak” out at a constant rate to your backend service. If the queue fills up, new requests are rejected.
This algorithm smooths traffic perfectly. No matter how bursty the incoming traffic, the downstream service sees a steady stream. The trade-off is latency—requests might wait in the queue even when the backend has capacity.
Leaky bucket is less common in API rate limiting but useful for traffic shaping scenarios where you’re protecting rate-sensitive downstream systems.
Making the Choice in Your Interview
When the interviewer asks “Which algorithm would you use?” don’t just pick one. Walk through your reasoning.
“Given our requirements—burst tolerance is acceptable, and approximate accuracy is fine—I’d choose token bucket with sliding window counter as a backup option. Token bucket handles the burst requirement naturally, and it’s well-understood in production systems.”
Then acknowledge the trade-off: “If we later discover burst traffic causes downstream issues, we could switch to sliding window counter with stricter limits. The interface stays the same—we’re just changing the internal implementation.”
This response demonstrates three senior-level skills: connecting requirements to technical choices, acknowledging that designs evolve, and recognizing that implementation details can change without breaking API contracts.
Data Storage & Schema Design
Your rate limiting algorithm is worthless without fast, reliable storage. The data model you choose determines performance, consistency, and operational complexity.
Most candidates say “we’ll use Redis” and move on. This is insufficient. Strong candidates explain what data they’re storing, why they’re storing it, and what happens when storage fails.
What Data Must You Store?
Your storage requirements flow directly from your chosen algorithm. Fixed window needs a counter and window start time. Sliding window log needs individual request timestamps. Token bucket needs current token count and last refill timestamp.
But all algorithms share common requirements: you need to identify whose limit you’re tracking (the key), and you need data to expire automatically when it’s no longer relevant (TTL).
Let’s design the schema for token bucket as an example. For each client, you need to store two values: the number of tokens currently available, and the timestamp of the last refill operation.
Key Design Patterns
How you structure keys affects everything from performance to debugging. A typical key pattern looks like:
ratelimit:{identifier_type}:{identifier}:{resource}
For example:
ratelimit:user:12345:api
or
ratelimit:ip:192.168.1.1:login
This hierarchical structure enables powerful operations. You can delete all rate limits for a specific user. You can query all rate limits for a particular resource. You can monitor memory usage by identifier type.
Keys should be human-readable for debugging. When you’re troubleshooting a production issue at 3am, you don’t want to decipher cryptic abbreviated keys.
📊 Table: Rate Limiter Schema Patterns by Algorithm
Each rate limiting algorithm requires different data structures and storage patterns. This table shows what you need to store, how to structure keys, and what TTL strategies work for each approach.
| Algorithm | Data Stored | Example Key | TTL Strategy | Memory per Client |
|---|---|---|---|---|
| Fixed Window | Counter, window start timestamp |
ratelimit:user:123:v1
|
Window duration (e.g., 1 hour) | O(1) – constant |
| Sliding Window Log | List of request timestamps |
ratelimit:log:user:123
|
Window duration | O(N) – N = request count |
| Sliding Window Counter | Current counter, previous counter, window start |
ratelimit:swc:user:123
|
2x window duration | O(1) – constant |
| Token Bucket | Token count, last refill timestamp |
ratelimit:bucket:user:123
|
Max idle time + window | O(1) – constant |
| Leaky Bucket | Queue of pending requests, last leak timestamp |
ratelimit:queue:user:123
|
Max queue time + window | O(M) – M = queue size |
Redis as the Default Choice
For most rate limiting use cases, Redis is the right choice. It provides fast in-memory operations, built-in TTL support, and atomic operations that prevent race conditions.
But don’t just say “Redis.” Explain why its specific features matter. The INCR command is atomic—multiple concurrent requests can safely increment the same counter. The EXPIRE command handles automatic cleanup. Sorted sets support sliding window log implementations efficiently.
For token bucket, a simple implementation uses two Redis keys:
tokens:{id}
stores the count, and
last_refill:{id}
stores the timestamp. Both get the same TTL. On each request, you calculate elapsed time, compute tokens to add, update both values, then check if tokens remain.
Memory Optimization Strategies
At scale, memory becomes a constraint. If you have 10 million active users and each rate limit consumes 100 bytes, that’s 1GB of Redis memory just for counters.
Optimization strategies emerge from this constraint. First, use shorter TTLs—data that expires quickly reduces steady-state memory. Second, choose algorithms wisely—sliding window counter uses constant memory regardless of request volume, while sliding window log grows with traffic.
Third, consider whether you need to track all users. If only 1% of users ever approach rate limits, you might track limits lazily—only creating entries when users make requests, letting them expire during idle periods.
Persistence vs. Pure Cache
Should rate limit data persist to disk? Most candidates assume not—rate limits are temporary, so why persist them?
But consider failure scenarios. If Redis crashes and restarts, all rate limit counters reset to zero. Abusive clients who were rate-limited suddenly get fresh allowances. This might be acceptable for your use case, or it might be a security problem.
The trade-off is clear: persistence protects against restart abuse but adds write latency and complexity. For most APIs, the ephemeral approach works fine—rate limits are short-term, and restart windows are brief enough that abuse risk is acceptable.
For high-security applications, you might persist limit data or implement rate limit memory that survives restarts using snapshot mechanisms.
Handling Data Store Failures
What happens when Redis goes down? This question separates thoughtful candidates from those who assume perfect infrastructure.
You have three options. First, fail open—allow all requests when you can’t check limits. This maintains availability but sacrifices protection. Second, fail closed—reject all requests when storage is unavailable. This protects your backend but creates terrible user experience.
Third, use local caching with best-effort limiting. Each API server maintains local counters as a fallback. When Redis is healthy, you use it for accurate distributed limiting. When Redis fails, you fall back to local counters—less accurate but better than nothing.
The right choice depends on your requirements. For public APIs, failing open might be acceptable. For critical infrastructure, failing closed or using cached limits makes sense. Discussing these options shows you’re thinking about production operations, not just happy-path algorithms.
Scaling the Rate Limiter (The Real Test)
Everything we’ve discussed so far works beautifully at small scale. A single Redis instance handling a few thousand requests per second is straightforward.
But when your interviewer asks “How would this scale to millions of requests per second across multiple data centers?”—that’s when the real system design interview begins.
This is where senior engineers separate from junior ones. Scaling isn’t just about adding more servers. It’s about understanding consistency trade-offs, failure modes, and operational complexity.
The Single-Node Limitation
Let’s start with the problem. Your single Redis instance can handle maybe 100,000 operations per second. What happens at 500,000 requests per second?
You need multiple rate limiter instances. But now each instance needs to share state—they all need to increment the same counters for the same users. Otherwise, each instance enforces limits independently, and your effective limit becomes N times higher than intended.
The naive solution: put a single Redis instance behind all rate limiter instances. But now Redis is your bottleneck again. You haven’t actually scaled—you’ve just moved the problem.
Distributed Rate Limiting Architecture
The production solution involves multiple levels of caching and eventual consistency. Each rate limiter instance maintains local counters that update frequently but not on every single request.
Here’s one approach: local rate limiters update Redis every 100 requests or every 5 seconds, whichever comes first. They track limits locally between syncs. This reduces Redis load by 100x while accepting that limits might be slightly exceeded during high-traffic periods.
The trade-off is explicit: you’re sacrificing perfect accuracy for scalability. Instead of exactly 1,000 requests per hour, you might allow 1,050. For most use cases, this approximation is acceptable—you’re protecting against abuse, not enforcing contracts with millisecond precision.
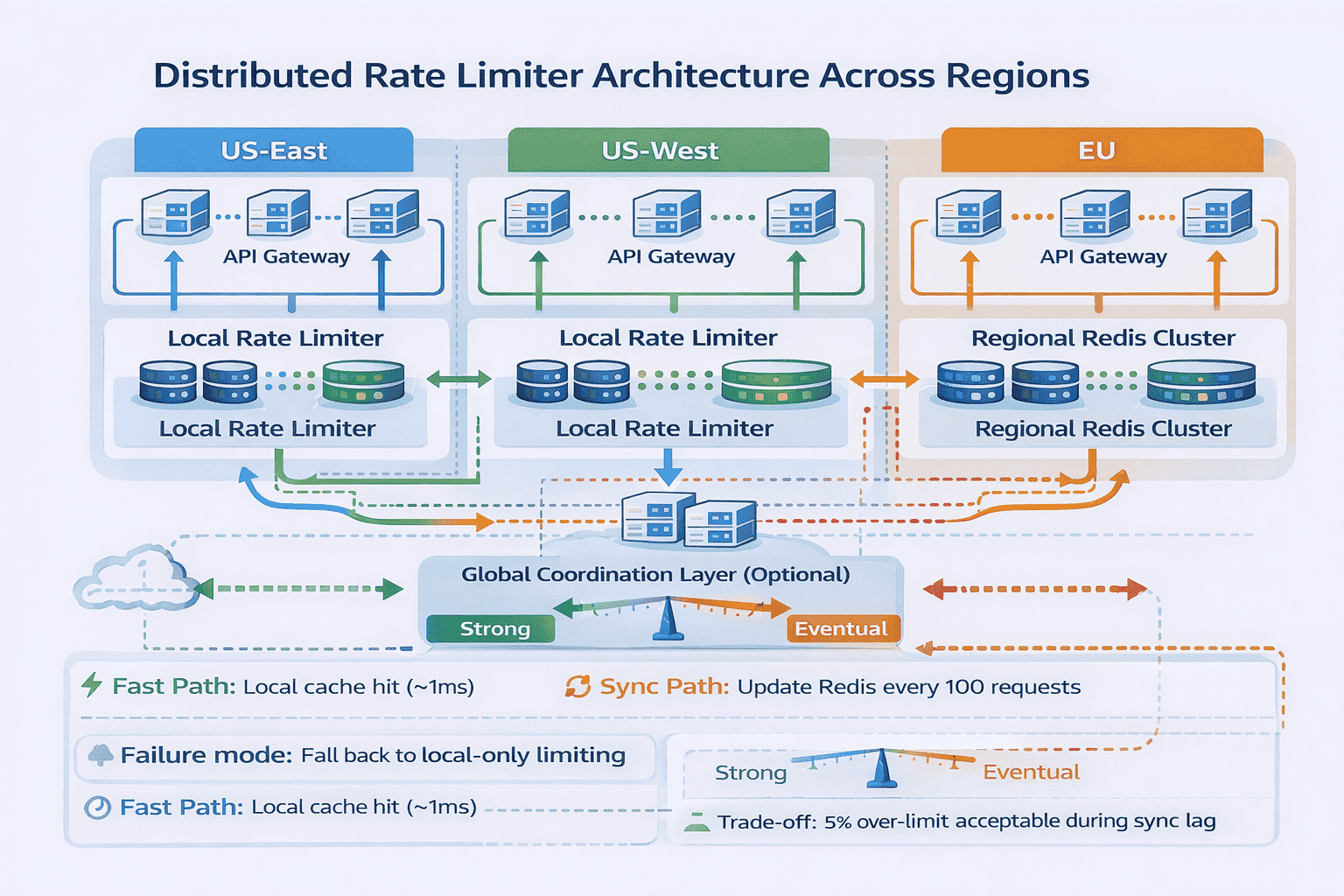
The Consistency Spectrum
When you distribute rate limiting across multiple nodes, you face the classic consistency-availability trade-off. Strong consistency means all nodes agree on the exact count at all times. Eventual consistency means nodes gradually converge on the correct count.
Strong consistency requires coordination—nodes must synchronize before making decisions. This adds latency and creates failure points. If the coordination service goes down, your rate limiter stops working.
Eventual consistency is faster and more resilient. Each node makes local decisions and syncs state periodically. Limits might be slightly exceeded during sync delays, but the system keeps working even when nodes can’t communicate.
For rate limiting, eventual consistency usually wins. The goal is protecting against abuse, not enforcing perfect mathematical accuracy. A 5-10% margin of error is acceptable if it means your rate limiter stays fast and available.
Handling Clock Drift
Distributed systems have a subtle problem: server clocks drift. One server thinks it’s 10:00:05am while another thinks it’s 10:00:03am. This matters when you’re implementing time-window-based algorithms.
If different rate limiter instances use different clocks, they’ll disagree about when windows start and end. A client could exploit this by routing requests to the instance with the “slowest” clock.
Solutions include using NTP to keep clocks synchronized (reducing drift to milliseconds), using logical clocks instead of wall clocks (like Lamport timestamps), or simply accepting that window boundaries are approximate in distributed systems.
Discussing clock drift shows you understand distributed systems deeply. Most candidates never mention it.
Partitioning Strategies
As you scale beyond one Redis instance, you need to partition data. How do you decide which Redis instance stores which user’s rate limit data?
Consistent hashing is the standard approach. Hash the user ID to determine which Redis node owns that user’s data. This distributes load evenly and minimizes data movement when adding or removing nodes.
But partitioning creates new failure scenarios. What if a Redis node fails? All rate limits for users on that node become unavailable. You need replication—each partition has a primary and one or more replicas.
During failover, there’s a brief window where limits might reset or become unavailable. Discussing how you’d handle this shows operational maturity: “We’d fail open for 5-10 seconds during Redis failover rather than rejecting all traffic for affected users.”
Multi-Region Complexity
Your interviewer escalates: “What if we’re running in three AWS regions globally? How do rate limits work across regions?”
Now you’re in truly challenging territory. Do you enforce limits globally or per-region? Global limiting requires cross-region coordination—slow and expensive. Per-region limiting is fast but allows 3x higher effective limits (if users can route to any region).
Most production systems use per-region limiting with global monitoring. Each region enforces its own limits independently. A separate system watches global traffic and can trigger emergency rate limit reductions if abuse is detected.
This hybrid approach acknowledges reality: global strong consistency is impractical for real-time rate limiting. Instead, you build layered defenses—fast local enforcement plus slower global monitoring.
Traffic Distribution Problems
Even with perfect partitioning, real-world traffic isn’t evenly distributed. Maybe one celebrity user generates 10x more traffic than typical users. Maybe a bot army attacks from a single IP range.
Hot partitions become bottlenecks. The Redis instance handling the celebrity’s rate limits maxes out while other instances sit idle. Standard partitioning strategies don’t help because the problem is data skew, not insufficient capacity.
Advanced solutions include detecting hot keys and replicating them across multiple nodes, allowing parallel rate limit checking. Or implementing hierarchical rate limiting—first check a coarse global limit, then check fine-grained per-user limits only for traffic that passes the first filter.
Graceful Degradation
Strong candidates always discuss failure modes. “When our rate limiter can’t reach Redis, we have three tiers of fallback.”
“Tier 1: Use local in-memory counters with best-effort limiting. Accuracy drops but availability stays high. Tier 2: If local memory fills up, switch to probabilistic limiting—randomly reject a percentage of requests. Tier 3: If the system is completely overwhelmed, fail open for known good clients based on historical patterns, fail closed for unknown or suspicious clients.”
This layered approach to failure handling demonstrates production thinking. Systems fail—the question is how gracefully they degrade, not whether they’ll work perfectly forever.
Trade-Offs & Decision Justification
System design interviews aren’t about finding the “correct” answer. They’re about navigating trade-offs and justifying decisions under constraints.
Strong candidates explicitly compare alternatives. They acknowledge what they’re sacrificing when they make architectural choices. This section walks through the key trade-offs in rate limiter design.
Accuracy vs. Performance
Perfect accuracy requires synchronization. Every rate limit check must see the absolute latest state across all nodes. This means distributed transactions or strong consistency—both slow and brittle at scale.
Approximate accuracy accepts eventual consistency. Nodes make decisions based on slightly stale data. Rate limits might be exceeded by 5-10% during peak traffic. But your system stays fast—sub-millisecond latency instead of 10-50ms for distributed consensus.
The question isn’t “which is better?” It’s “what does your use case require?” Preventing payment fraud demands accuracy. Protecting against DDoS attacks tolerates approximation. Different requirements, different choices.
Simplicity vs. Flexibility
A simple rate limiter has one rule: X requests per hour, applied globally. Easy to understand, easy to implement, easy to operate. But it can’t handle nuanced requirements—different limits for different endpoints, burst allowances, tiered access levels.
A flexible rate limiter supports complex policies: 1000 reads per hour, 100 writes per hour, burst up to 50 requests per second, premium users get 10x higher limits. Powerful, but now you need a policy engine, configuration management, and extensive testing.
Most systems start simple and add complexity only when needed. “We’ll launch with fixed hourly limits. If customers request tiered access, we’ll add a policy engine. Starting simple lets us validate the core infrastructure before adding features.”
📊 Table: Rate Limiter Design Trade-Off Analysis
Every architectural decision in rate limiter design involves trade-offs between competing priorities. This table helps you evaluate options systematically and justify your choices in interviews.
| Trade-Off Dimension | Option A | Option B | When to Choose A | When to Choose B |
|---|---|---|---|---|
| Accuracy vs Performance | Strong consistency, exact limits | Eventual consistency, ~5% margin | Financial transactions, security-critical APIs | Public APIs, high-traffic services |
| Simplicity vs Flexibility | Single global limit rule | Per-endpoint policies, tiered access | MVP launch, internal APIs | Multi-tenant SaaS, premium tiers |
| Latency vs Consistency | Local cache, fast decisions | Distributed coordination, slower | User-facing APIs (<10ms target) | Background jobs, batch operations |
| Memory vs Accuracy | Sliding window log, high memory | Fixed window, constant memory | Low traffic, security-focused | High traffic, cost-sensitive |
| Availability vs Protection | Fail open when storage down | Fail closed when storage down | Customer-facing services, revenue | Admin endpoints, sensitive operations |
| Centralized vs Distributed | API gateway rate limiting | Service-level rate limiting | Uniform limits, simple operations | Operation-specific costs, microservices |
Latency vs. Consistency
Fast rate limiting means local decisions without coordination. Each node checks limits based on local state and cached data. Response time stays under 1 millisecond. But global limits might be exceeded when traffic spikes hit multiple nodes simultaneously.
Consistent rate limiting means coordinating across nodes before making decisions. You know the exact global state. But coordination takes time—10-50 milliseconds for cross-data-center consensus. For APIs where every millisecond matters, this latency is unacceptable.
The middle ground: use local limiting for fast common cases, fall back to coordinated limiting only when local counters suggest you’re near limits. “99% of requests get sub-millisecond latency. The 1% near limits take 10ms for accurate checking. Users don’t notice because we’re only slow when we’re about to reject them anyway.”
Cost vs. Accuracy
Running large Redis clusters costs money. Sliding window log implementations storing individual timestamps for millions of users can require significant memory—easily thousands of dollars monthly at scale.
Fixed window counters using constant memory cost far less. But they allow boundary exploitation. Is preventing that edge case worth 10x higher infrastructure costs?
Production systems often choose cheaper approximate solutions. “We’ll use sliding window counter instead of sliding window log. We accept 5% boundary exploitation risk to save $15,000 monthly on Redis memory. If abuse becomes a problem, we can tighten limits or upgrade the algorithm.”
Feature Richness vs. Operational Complexity
Advanced features sound great in design docs. Support for multiple simultaneous limit types (per-second AND per-hour AND per-day). Complex policies with conditionals. Different limits per endpoint, per client tier, per geographic region.
But features create operational burden. More configuration means more opportunities for mistakes. Complex policies are harder to debug. “Why was this request rejected?” becomes a difficult question when seven different rules might apply.
Start with the simplest system that solves the core problem. “We’ll launch with single-tier hourly limits. When customers request premium access, we’ll add tiered limiting. When we see regional abuse patterns, we’ll add geographic rules. Each feature is justified by actual needs, not theoretical requirements.”
How to Present Trade-Offs in Interviews
Don’t just list options. Walk through your reasoning: “Given our requirements—sub-5ms latency target and 1 million RPS—I’d choose local caching with eventual consistency. Here’s what we’re trading off…”
“We’re sacrificing perfect accuracy. Limits might be exceeded by ~5% during traffic spikes. But we’re gaining speed—every request gets answered in under 2ms. And we’re gaining resilience—the system works even when Redis is temporarily unavailable.”
“If we later discover the accuracy trade-off causes problems, we could tighten limits by 5% to compensate, or move to stronger consistency for specific high-value endpoints while keeping eventual consistency for everything else.”
This narrative demonstrates senior thinking: understanding that designs evolve, that perfect solutions don’t exist, and that trade-offs shift as requirements change.
Your Path to Rate Limiter Mastery
You’ve walked through an entire rate limiter design from first principles. Not as theory to memorize, but as decisions to understand.
Wondering whether paid guidance is worth it for your interview goals? Read Is System Design Interview Coaching Worth It?.
The real insight? Rate limiter interviews test whether you can navigate ambiguity systematically. Can you clarify requirements before building? Can you start simple and evolve complexity? Can you acknowledge trade-offs without claiming your design is perfect?
These skills extend far beyond rate limiting. They’re how senior engineers approach every system design problem.
The Complete Interview Walkthrough
Here’s how a strong candidate explains this entire design in 10-12 minutes, tying everything together.
“I’d start by clarifying requirements. Are we limiting by user ID, IP, or API key? What scale—thousands or millions of requests per second? Are bursts acceptable? Is exact accuracy required?”
“Let’s say we’re limiting by user ID, handling 500,000 requests per second, bursts are acceptable, and approximate accuracy is fine. I’d sketch a high-level design: clients hit an API gateway, which checks rate limits before forwarding to backend services.”
“For the algorithm, token bucket fits well—it handles bursts naturally. For storage, I’d use Redis with a key pattern like
ratelimit:user:{id}
storing token count and last refill timestamp.”
“To scale, I’d add local caching at each gateway instance. They sync to Redis every 100 requests or 5 seconds. This reduces Redis load 100x while accepting ~5% over-limit during sync delays. If Redis fails, we fall back to local-only limiting.”
“For the API contract, successful requests get headers showing remaining quota and reset time. Rejected requests return 429 with Retry-After headers.”
“Trade-offs: we’re choosing performance over perfect accuracy, simplicity over feature richness, and availability over strict protection. Each choice makes sense for our requirements, and we can adjust if needs change.”
📥 Download: Rate Limiter Interview Prep Checklist
This one-page checklist covers every topic interviewers expect you to address when designing a rate limiter. Use it to practice your verbal walkthrough and ensure you’re not missing critical discussion points.
Download PDFCommon Variations Interviewers Introduce
Once you’ve presented the basic design, interviewers often add constraints to see how you adapt. Be ready for these variations.
Variation 1: “What if we need different limits per endpoint?”
Add endpoint information to your key pattern:
ratelimit:user:{id}:endpoint:{name}
. Store separate counters for each endpoint-user combination. The trade-off is higher memory usage but more flexible limiting.
Variation 2: “How would you implement tiered access (free vs. premium users)?”
Store limit configuration separately from counters. When checking limits, look up the user’s tier first, then apply the appropriate limit value. Premium users might get 10,000 requests per hour while free users get 1,000.
Variation 3: “What if abuse patterns change and we need to adjust limits in real-time?”
Separate your limit configuration from your enforcement logic. Store limits in a configuration service that can be updated without redeploying code. Rate limiter instances poll for config changes every few seconds and apply updated limits immediately.
Practicing for Your Interview
Reading this guide isn’t enough. You need to practice verbalizing the design until it flows naturally.
Set a 12-minute timer. Pretend you’re in the interview. Talk through the entire design out loud, from requirement clarification to trade-off justification. Record yourself if possible—you’ll catch where you’re unclear or spending too long on minor details.
Practice with variations. “How would this change if we needed per-IP limiting instead of per-user?” Work through the implications: no authentication required, but IP addresses change, NATs create shared IPs, mobile clients hop between IPs frequently.
The goal isn’t memorizing answers. It’s building mental models you can apply to any system design problem, whether it’s rate limiting, URL shortening, or distributed caching.
Beyond the Interview: Production Considerations
If you’re implementing rate limiting in production, several additional concerns emerge that interviews rarely cover.
Monitoring becomes critical. You need dashboards showing current usage per user, rejection rates, and Redis performance. Alerts when rejection rates spike unexpectedly—this might indicate a misconfigured limit or an actual attack.
Testing is harder than you’d think. Unit testing rate limiting logic is straightforward, but integration testing with realistic traffic patterns requires sophisticated tooling. How do you verify that your distributed rate limiter with eventual consistency behaves correctly under load?
Documentation matters. When a customer emails asking “why was my request rejected?”, support needs clear answers. Document your policies, explain the limits, and provide self-service tools for checking current usage.
Learning from Real-World Systems
Study how major APIs implement rate limiting. GitHub’s API returns detailed rate limit headers and has separate limits for different endpoint categories. Stripe uses sophisticated algorithms that adapt limits based on account history and payment success rates.
Read postmortems about rate limiting failures. Cloudflare has published excellent technical writeups about how they scaled rate limiting to handle DDoS attacks at massive scale. These real-world cases reveal complexities that interview questions gloss over.
The patterns you learn from rate limiting apply everywhere. The consistency-availability trade-off shows up in distributed databases. The local caching pattern appears in CDNs. The policy vs. enforcement separation is fundamental to authorization systems.
Your Next Steps
Master rate limiter design as your foundation, then practice related problems. Design a URL shortener—it has similar scaling challenges. Design a distributed cache—it shares consistency trade-offs. Design an API gateway—rate limiting is one of many features it needs.
Each problem reinforces the same core skills: requirement clarification, progressive refinement, trade-off analysis, and clear communication under pressure.
When you can explain rate limiter design naturally, adapting to constraints and justifying decisions, you’re ready for any system design interview. The specific problem changes, but the thinking process stays the same.
Frequently Asked Questions
What’s the most common mistake in rate limiter design interviews?
Jumping straight to implementation without clarifying requirements. Candidates immediately start discussing Redis and token buckets without asking whether limits are per-user or per-IP, whether bursts are acceptable, or what scale we’re targeting. These questions aren’t stalling—they determine which design choices are appropriate. Spend the first 3-5 minutes clarifying requirements; it shows you understand that context drives architecture decisions.
Which rate limiting algorithm should I choose in an interview?
There’s no universally “correct” algorithm. The right choice depends on your clarified requirements. If bursts are acceptable and you need simple implementation, token bucket works well. If exact accuracy matters and traffic is moderate, sliding window log is appropriate. If you need constant memory usage at high scale, sliding window counter or fixed window makes sense. Strong answers connect algorithm properties to specific requirements: “Given that we need burst tolerance, I’d choose token bucket because…” Don’t just pick an algorithm—justify it.
How do I handle the scaling question when I’ve never built distributed systems?
Acknowledge your experience level honestly, then reason through the problem systematically. Start with single-node limitations: “One Redis instance handles ~100K ops/sec. At 1M requests/sec, we need distributed architecture.” Then discuss the trade-off: “Perfect accuracy requires coordination across nodes, which adds latency. Approximate accuracy with local caching is faster but might exceed limits by 5-10%.” This demonstrates understanding of fundamental distributed systems concepts even without direct implementation experience.
Should I mention specific technologies like Redis, or keep the design abstract?
Mention specific technologies but explain why they fit. Saying “we’ll use Redis” without justification is hollow. Instead: “I’d use Redis because it provides atomic increment operations, built-in TTL support, and sub-millisecond latency we need for this use case. The INCR command prevents race conditions when multiple requests increment the same counter simultaneously.” This shows you understand both the requirements and how specific technology features address them.
What if the interviewer asks about edge cases I haven’t considered?
Think out loud and work through the problem collaboratively. If asked “what happens during clock skew between servers?”, you might say: “That’s a good point. Different server clocks would create inconsistent window boundaries. We could use NTP to keep clocks synchronized within milliseconds, or we could accept that window boundaries are approximate in distributed systems and use logical timestamps instead.” Admitting you hadn’t considered something, then reasoning through a solution, is better than claiming you had thought of everything.
How detailed should I get about implementation specifics?
Match your depth to the time available and interviewer’s interest. In a 45-minute interview, spend 5 minutes on requirements, 10 minutes on high-level design, 15 minutes on algorithm and storage, 10 minutes on scaling, and 5 minutes on trade-offs. If the interviewer asks “how would you implement this in code?”, sketch pseudocode for the core logic. But don’t dive into implementation details unprompted—system design interviews test architectural thinking, not coding ability. Stay at the level where you’re making meaningful design decisions, not writing production code.
Citations
- https://redis.io/docs/manual/patterns/rate-limiter/
- https://stripe.com/blog/rate-limiters
- https://konghq.com/blog/how-to-design-a-scalable-rate-limiting-algorithm
- https://blog.cloudflare.com/counting-things-a-lot-of-different-things/
- https://developer.github.com/v3/rate_limit/
- https://www.nginx.com/blog/rate-limiting-nginx/
Content Integrity Note
This guide was written with AI assistance and then edited, fact-checked, and aligned to expert-approved teaching standards by Andrew Williams . Andrew has over 10 years of experience coaching software developers through technical interviews at top-tier companies including FAANG and leading enterprise organizations. His background includes conducting 500+ mock system design interviews and helping engineers successfully transition into senior, staff, and principal roles. Technical content regarding distributed systems, architecture patterns, and interview evaluation criteria is sourced from industry-standard references including engineering blogs from Netflix, Uber, and Slack, cloud provider architecture documentation from AWS, Google Cloud, and Microsoft Azure, and authoritative texts on distributed systems design.

