System Design Interview Prep: The Definitive Guide to Landing L5+ Roles.
You’ve spent years building distributed systems. You’ve scaled databases, optimized APIs, and debugged production incidents at 3 AM. Yet when you sit down for a system design interview preparation session something feels…
You’re not alone Senior engineers with 8 years of experience fail system design interviews at companies they’re overqualified for The disconnect isn’t about technical competence it’s about understanding… If you’re choosing between structured guidance and free content, see System Design Coaching vs YouTube for interview prep.
This guide gives you the complete framework what system design interviews test how companies score you why capable engineers fail and the repeatable process to prepare strategically in 2-12…
Last updated: Feb. 2026
Table of Contents
- 1. Why Senior Engineers Struggle With System Design Interviews
- 2. What a System Design Interview Really Tests
- 3. How Companies Evaluate You (The Hidden Rubric)
- 4. Why Candidates Fail (Even With Good Knowledge)
- 5. The Complete Interview Framework (Your Default Flow)
- 6. Core Building Blocks You Must Master
- 7. Reliability & Production Thinking (What Most Candidates Miss)
- 8. Security & Abuse Prevention (Interview-Ready Version)
- 9. Frequently Asked Questions
Contents
Why Senior Engineers Struggle With System Design Interviews
The expertise paradox explains why senior engineers often perform worse in system design interviews than mid-level candidates Years of production experience create mental shortcuts and assumptions that work…
Real-World Engineering Versus Interview Performance
In production systems, you inherit constraints. The database technology is already chosen. Caching strategies evolved over years. Architecture decisions happened before you joined.
You optimize within existing boundaries. Senior engineers excel at this—debugging bottlenecks, improving specific subsystems, and shipping incremental improvements. This is valuable work.
System design interviews test the opposite skill Starting from zero requirements you must make architectural choices justify tradeoffs and design systems that don’t exist yet Many experienced engineers… If you’re worried you lack design background, read How to crack system design interviews without prior design experience.
The Communication Gap That Kills Strong Candidates
Production engineering rewards speed and efficiency. You see a caching problem, add Redis , move on. No explanation needed—your commit speaks for itself.
Interviews reward explicit communication The interviewer cannot see inside your head When you jump from we need fast lookups to let’s use Redis without explaining the tradeoff between…
Senior engineers make these tradeoffs constantly but rarely verbalize the decision tree. The interview format penalizes this implicit knowledge.
📊 Table: Production Work vs. Interview Expectations
This comparison shows why real-world engineering skills don’t directly transfer to interview performance. Understanding these differences helps you prepare strategically.
| Production Engineering | System Design Interview | Why This Matters |
|---|---|---|
| Optimize existing systems | Design new systems from scratch | Different problem-solving mode required |
| Work within established constraints | Define constraints yourself | Must ask clarifying questions proactively |
| Implementation details matter | High-level tradeoffs matter more | Candidates often go too deep too fast |
| Code and commits speak for themselves | Must verbalize all decision-making | Communication is 50% of the evaluation |
| Single correct solution often exists | Multiple valid approaches exist | Showing tradeoff awareness beats “perfect” design |
Anxiety Amplifies the Disconnect
Capable engineers fail interviews because performance anxiety triggers self-disqualification. You know you could build this system in production. The artificial interview setting feels contrived.
This frustration creates a vicious cycle Annoyance leads to rushing Rushing leads to skipping requirement clarification Skipping requirements leads to designing the wrong system The interviewer flags lack…
Breaking this cycle requires recognizing that system design interviews test a specific learnable skillset distinct from engineering ability The preparation process addresses both the technical framework and the…
The Preparation Mismatch
Most engineers prepare by memorizing architecture patterns. They study Netflix’s microservices, Google’s Bigtable, Amazon’s DynamoDB. They can explain consistent hashing, CAP theorem, and eventual consistency.
Then the interview asks them to design Uber They freeze The pattern library doesn’t map directly to this specific problem They try to retrofit memorized solutions creating Frankenstein…
Effective preparation focuses on process over patterns Learn the systematic approach to breaking down any problem clarify scope identify constraints start simple justify choices handle objections Patterns become…
What a System Design Interview Really Tests
System design interviews evaluate structured thinking and communication under ambiguous conditions Companies use this format to predict how you’ll handle architectural decisions in real senior roles where requirements…
The Interview Format Spectrum
Formats vary by company and level. Understanding these variations prevents surprises.
Duration ranges from 45 to 90 minutes. FAANG companies typically allocate 45 minutes. Startups and scale-ups often run 60-minute sessions. Some companies split system design across multiple rounds.
Medium choices include whiteboarding, collaborative docs, or diagramming tools. In-person interviews use physical whiteboards Remote interviews shifted to tools like Miro Excalidraw or Google Docs Some companies provide…
Interviewer styles range from hands-off to highly interactive. Some interviewers barely speak after stating the problem observing how you handle ambiguity Others actively probe decisions challenge assumptions and…
The Seven Core Evaluation Signals
Companies assess candidates across these dimensions, though weighting varies by role and level.
Problem framing: Do you clarify requirements before designing Can you distinguish functional requirements what the system does from non-functional requirements how well it performs Do you identify the…
Weak candidates jump into architecture immediately. Strong candidates spend 5-7 minutes ensuring they’re solving the right problem.
Tradeoff navigation : Every architectural choice involves tradeoffs SQL databases offer strong consistency but harder horizontal scaling NoSQL databases scale easily but sacrifice transaction guarantees Do you articulate these tradeoffs clearly…
This signal differentiates senior from junior engineers. Juniors present solutions. Seniors present decisions with explicit reasoning.
Communication clarity: Can the interviewer follow your thought process? Do you state assumptions explicitly? Do you check for understanding before diving deeper? Do you structure your explanation logically?
Many technically sound designs earn “no hire” because the interviewer couldn’t follow the candidate’s reasoning. If you’re thinking faster than you’re explaining, slow down.
Appropriate depth: Knowing when to stay high-level versus when to drill deep is critical You cannot fully design every component in 45 minutes Strong candidates present the high-level…
Going too deep into one area signals poor time management. Staying too shallow everywhere signals superficial understanding.
Scalability considerations: Can you identify bottlenecks before they’re pointed out Do you consider what happens at 10x scale At 100x scale Do you know which components become problematic…
Scalability doesn’t mean “add more servers.” It means understanding where sequential operations create throughput limits, where data locality matters, and where coordination costs dominate.
Reliability and failure handling: Real systems fail Drives crash networks partition services hang Do you design for partial failures Do you consider retry logic circuit breakers and graceful…
This signal matters more for senior and staff levels. Companies want confidence you’ll build production-ready systems, not theoretical architectures.
Cost awareness: Not every problem requires Google-scale infrastructure. Do you consider operational costs? Can you justify expensive components? Do you identify opportunities to reduce cost without sacrificing requirements?
This skill becomes increasingly important as you target staff+ roles where business impact matters alongside technical execution.
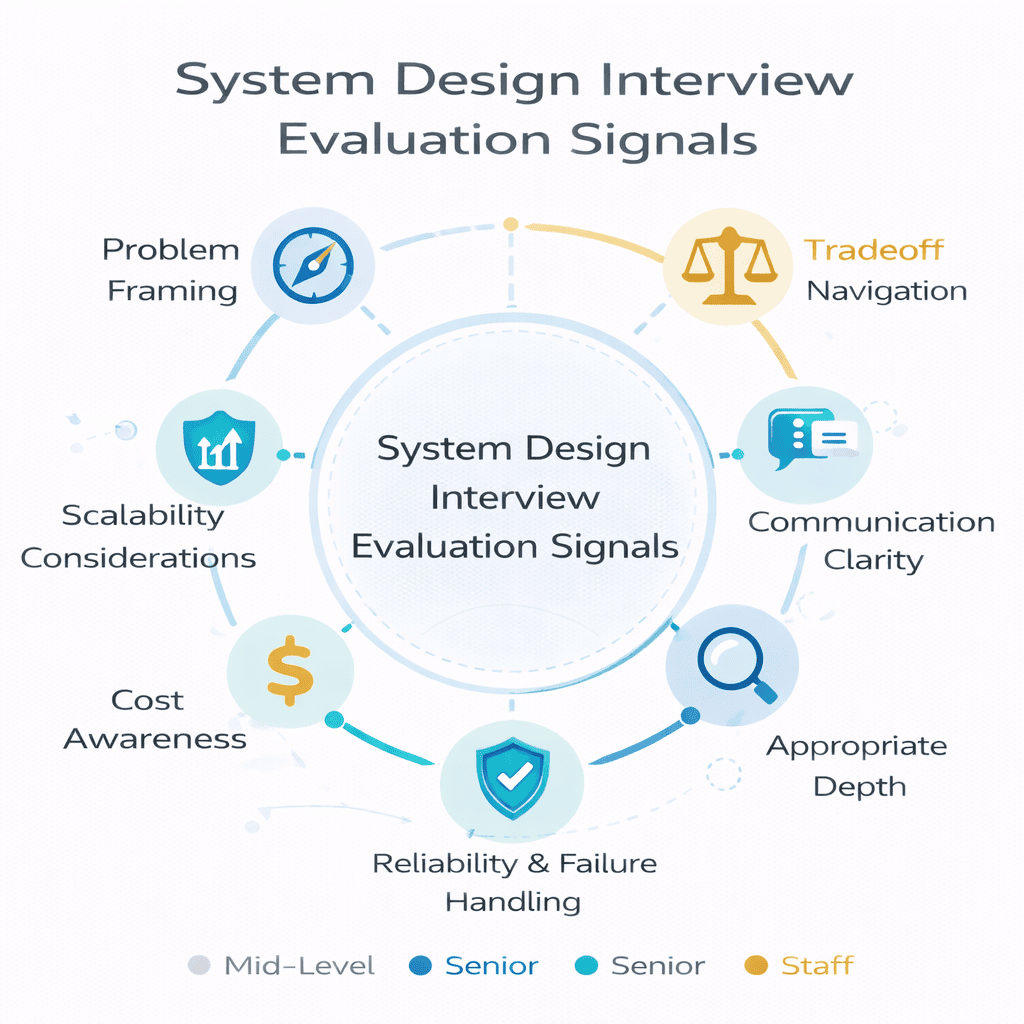
How Signals Map to Seniority Levels
Expectations scale with job level. Understanding these differences helps you calibrate your preparation.
Mid-level engineers (L4/E4) should demonstrate solid problem framing reasonable architectural choices and awareness of basic scalability patterns Deep tradeoff analysis and sophisticated reliability thinking are bonuses not…
Senior engineers (L5/E5) must excel at tradeoff navigation and communication Interviewers expect you to drive the conversation proactively identify edge cases and handle challenging follow-up questions about…
Staff engineers (L6/E6+) face scrutiny on cost awareness operational complexity and system evolution over time Can you design systems that teams can maintain Do you consider migration…
What Interviewers Probe During Deep Dives
After you present the high-level design, interviewers drill into specific areas. These probes test depth of understanding.
Bottleneck identification: What part of this system becomes the bottleneck at 10 million requests per second Strong candidates immediately identify the write path database contention points or network…
Failure mode analysis: What happens if the cache layer goes down This tests whether you’ve thought beyond happy path Can you describe graceful degradation Do you understand cascading…
Consistency guarantees: Does this design guarantee that users see their own writes immediately This probes understanding of CAP theorem implications Many candidates claim eventual consistency without understanding what…
Cost estimation: “How much would this cost to run at 1 million users?” This tests back-of-the-envelope calculation ability and infrastructure cost awareness. Ballpark accuracy matters more than precision.
How Companies Evaluate You (The Hidden Rubric)
Every company uses a scoring rubric to standardize interview feedback Understanding these rubrics transforms abstract advice into concrete actions You can optimize your performance when you know exactly…
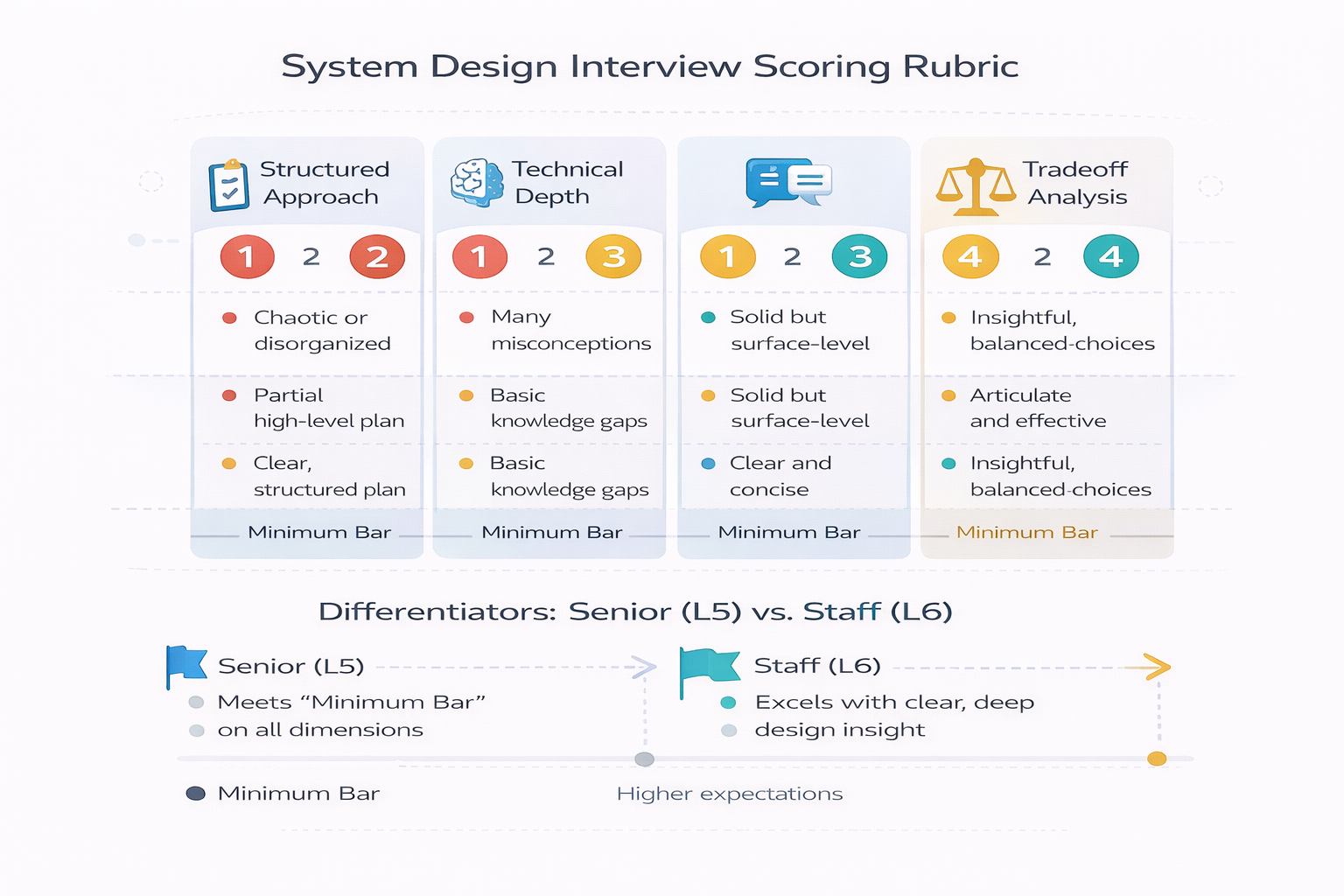
The Standard Rubric Structure
Most tech companies evaluate system design interviews across four to six categories Each category receives a score from 1 to 4 where 1 means significant concerns and 4…
Structured approach and problem-solving: Did the candidate ask clarifying questions Did they define requirements before jumping into solutions Did they break the problem into manageable pieces This category…
A score of 2 here means you eventually got to a solution but took wrong turns or needed heavy prompting A score of 4 means you drove the…
Technical depth and breadth: Does the candidate understand how different components work Can they explain why they chose specific technologies Do they know the tradeoffs between alternatives This…
Many candidates score well on breadth they mention caching load balancers databases but poorly on depth they can’t explain when to use Redis vs Memcached or why Strong…
Communication and collaboration: Could the interviewer follow your thinking Did you explain clearly Did you respond well to questions and pushback Did you think out loud or go…
This category kills otherwise strong candidates You might design a perfect system but if the interviewer struggled to understand your reasoning you’ll score a 2 Remember the interviewer…
Tradeoff analysis and decision-making: Did you articulate the pros and cons of different approaches Did you justify your choices based on requirements Did you show awareness of what…
Weak candidates make assertions We’ll use a NoSQL database because it’s scalable Strong candidates make arguments Given our read-heavy workload with eventual consistency tolerance a NoSQL database like…
How Senior Versus Staff Rubrics Differ
The evaluation categories stay similar across levels, but the bar for each score shifts higher. What earns a 4 at mid-level might earn a 3 at senior level.
Senior engineer expectations (L5/E5): You should drive the interview independently The interviewer might stay quiet for 10-15 minutes while you work through requirements and initial design You…
At this level interviewers expect you to say things like Before we continue I should verify our consistency requirements because that affects database selection or Let me walk…
Staff engineer expectations (L6/E6+): Everything from senior level plus demonstrated thinking about system evolution team scalability and operational burden Can you explain how this system changes when…
Staff candidates should volunteer observations about organizational complexity This design introduces operational overhead because now we need expertise in both PostgreSQL and Cassandra We should consider whether the…
What “Good” Actually Looks Like in Practice
Abstract rubric categories become concrete when you see example behaviors that earn high scores versus low scores.
High score behavior for structured approach: Let me make sure I understand the requirements We’re building a URL shortener I’m assuming we need to support creating short URLs…
This demonstrates requirement clarification, scope definition, and scale awareness in two sentences.
Low score behavior for structured approach: Okay URL shortener I’ll use a hash function to create short codes store them in a database and when someone clicks the…
This jumps directly to implementation without clarifying requirements or considering alternatives. The interviewer has no insight into your thinking process.
High score behavior for tradeoff analysis: For the database choice I’m weighing two options SQL databases like PostgreSQL give us strong consistency and relational capabilities which helps if…
This shows structured comparison, requirement-driven reasoning, and explicit choice with justification.
Low score behavior for tradeoff analysis: “We’ll use NoSQL because it’s more scalable and modern applications use it.”
This reveals cargo-cult thinking without understanding tradeoffs. The terms “scalable” and “modern” are vague and don’t connect to specific requirements.
Reading Interviewer Signals During the Session
Attentive candidates pick up on interviewer cues and adjust their approach. These signals help you course-correct in real-time.
Positive signals: The interviewer nods along takes notes actively asks clarifying questions about your reasoning Why did you choose X over Y and probes deeper into specific areas…
These signals mean you’re on track. Continue your current approach and maintain communication clarity.
Neutral signals: The interviewer stays quiet doesn’t interrupt but also doesn’t show strong engagement They might look at their notes more than at you They respond with okay…
Neutral signals suggest you’re not providing enough insight into your thinking Increase verbal explanation of your reasoning Check in more frequently Does this approach make sense or Should…
Warning signals: The interviewer interrupts to redirect you asks you to restart or says things like Let’s take a step back or I’m not sure I follow They…
Warning signals mean you’ve gone off track. Stop, clarify what confused them, and reset. Don’t defend your approach defensively—interviewers test how you handle feedback and course-correction.
The Calibration Process Behind Hiring Decisions
After your interview, your scores enter a calibration meeting where hiring managers compare candidates. Understanding this process explains why borderline performance sometimes results in offers and sometimes doesn’t.
Score comparison across interviewers: If you interviewed with multiple people they compare notes Consistent scores all 3s or all 3-4s make decisions straightforward Mixed scores one 4 two…
Comparison to interview bar: Each company maintains internal benchmarks examples of what strong yes versus weak yes versus no hire looks like for each level Your performance gets…
Headcount availability and urgency: Two identical candidates might receive different outcomes based on hiring timeline and open positions Early in a hiring cycle companies might pass on borderline…
This reality is frustrating but important to understand. Sometimes rejection reflects external factors beyond your control, not your actual capability.
Why Candidates Fail (Even With Good Knowledge)
The gap between knowing system design patterns and performing well in interviews explains why smart engineers repeatedly fail These failure modes are predictable and fixable once you recognize…
Jumping Into Architecture Without Requirements
This is the single most common failure mode The interviewer asks Design Instagram and you immediately start Okay we’ll need a photo storage service a feed generation system…
You just wasted the entire interview Instagram has dozens of features Does this interview focus on photo upload feed generation search direct messaging or stories Is the priority…
Without clarifying requirements, you’re designing a system the interviewer didn’t ask for. Even if your architecture is technically sound, you’ll score poorly on “structured approach” and “problem-solving.”
The fix: Spend the first 5-7 minutes on requirements Ask What are the core features we need to support What’s the scale users requests per second data volume…
Write these down visibly. Refer back to them throughout the interview. This shows structured thinking and prevents you from designing the wrong system.
Over-Designing for Scale
You hear design Twitter and immediately propose a complex microservices architecture with dedicated services for timelines notifications recommendations ads messaging and more You add Kafka for real-time streams…
The interviewer asks How many users You say Let’s assume 10 000 initially Now your massive infrastructure looks absurd You’ve over-engineered a solution that could run on a…
Strong candidates start simple and scale incrementally. Design for actual requirements, then explain how you’d evolve the architecture as load increases.
The fix: Begin with the simplest architecture that meets requirements A monolith with a database often works for the initial design Then say At 100x scale this component…
Under-Designing and Staying Too Vague
The opposite problem also fails interviews You draw boxes labeled web server cache and database without explaining what they do how they interact or why you chose them…
This signals superficial understanding. Anyone can draw a three-tier architecture. The interview tests whether you understand the implications of your choices.
The fix: After presenting high-level architecture pick 2-3 components to explain in detail Let me drill into the caching layer We’re using Redis rather than Memcached because we…
This depth shows you understand not just what the component does but why it exists and what tradeoffs it introduces.
📊 Table: Common Failure Modes and How to Avoid Them
Recognizing these patterns in your practice sessions helps you course-correct before real interviews. Each failure mode has a specific prevention strategy.
| Failure Mode | What It Looks Like | Why It Fails | How to Fix It |
|---|---|---|---|
| Skipping Requirements | Jumping straight to architecture | Solving wrong problem | Force 5-7 min requirement phase |
| Over-Engineering | Kafka + microservices for 10K users | Poor judgment on scale | Start simple, scale incrementally |
| Under-Engineering | Vague boxes without details | Shallow understanding | Deep-dive 2-3 components |
| Weak Tradeoffs | “Use NoSQL because it’s scalable” | Cargo-cult reasoning | State alternatives + criteria + choice |
| Ignoring Reliability | Only happy path, no failures | Not production-ready | Proactively mention retries, fallbacks |
| Poor Time Management | 30 min on API design 5 min on… | Missed critical sections | Timebox 7 min requirements 25 min design 10… |
Providing Weak Tradeoff Explanations
You choose a technology and the interviewer asks why. You respond with vague platitudes: “It’s scalable,” “It’s fast,” “It’s what modern companies use,” “I’ve worked with it before.”
None of these answers demonstrate understanding Everything is scalable given proper architecture Everything is fast for some workloads and slow for others Personal familiarity doesn’t justify architectural choices…
The fix: Structure tradeoff explanations as Alternative A versus Alternative B based on Criterion X from requirements I choose A because of specific reason Y with tradeoff Z…
Ignoring Reliability and Operations
You design a beautiful architecture for the happy path Every component has a clear purpose The data flows elegantly Then the interviewer asks What happens when the cache…
Production systems fail constantly. Drives fail, networks partition, deployments break things, traffic spikes overwhelm services. Designs that ignore failure modes signal lack of production experience.
The fix: After presenting your initial design volunteer reliability considerations without prompting Let me talk through failure scenarios If the cache fails requests hit the database directly We’ll…
This proactive reliability thinking differentiates senior candidates from junior ones.
Not Managing Time Boxes
You spend 25 minutes perfecting the API design covering every endpoint parameter in detail Then you have 10 minutes left to design the entire backend architecture which you…
Or you get stuck on one component, spending 15 minutes debating caching strategies while ignoring database design, networking, and scaling concerns entirely.
Poor time management signals weak prioritization skills. In real senior roles, you must judge where to invest effort and where to move quickly.
The fix: Mentally allocate time before you start In a 45-minute interview 5-7 minutes requirements 5 minutes high-level architecture 20 minutes deepening 2-3 areas 5-10 minutes handling follow-ups…
Going Silent for Long Periods
The interviewer asks a question and you think for 90 seconds without speaking Your facial expression shows active thinking but the interviewer has no idea what’s happening in…
Long silences hurt your communication score and make interviewers nervous. They can’t evaluate your thought process if you don’t share it.
The fix: Think out loud continuously Okay let me work through the caching strategy I’m considering where cache misses create bottlenecks The read path has 100x more traffic…
This stream-of-consciousness approach might feel awkward initially but it gives interviewers insight into your problem-solving process Even if you don’t reach the perfect solution strong reasoning visible throughout…
The Complete Interview Framework (Your Default Flow)
This framework provides a repeatable process for any system design problem Memorize this flow until it becomes automatic When nervousness hits during interviews this structure keeps you on…
Phase 1: Clarify the Problem (5-7 Minutes)
Never skip this phase. Requirements clarification separates structured thinkers from reactive problem solvers. See the step-by-step approach .
Identify core features: Ask What are the key features this system needs to support For a ride-sharing app is it just matching riders with drivers or does it…
Define scale and performance targets: Numbers matter Ask How many users How many requests per second How much data storage A system for 10 000 users looks completely…
Understand constraints and priorities: Ask Are there latency requirements Does this need to work globally or in specific regions Is consistency critical or is eventual consistency acceptable Do…
These questions reveal what matters most. A financial transaction system requires strong consistency. A social media feed tolerates eventual consistency for better performance.
Clarify what’s in scope versus out of scope: You cannot design every feature in 45 minutes Confirm which parts matter for this interview Should I focus on the…
Write down the answers visibly. Point to them later when making design choices.
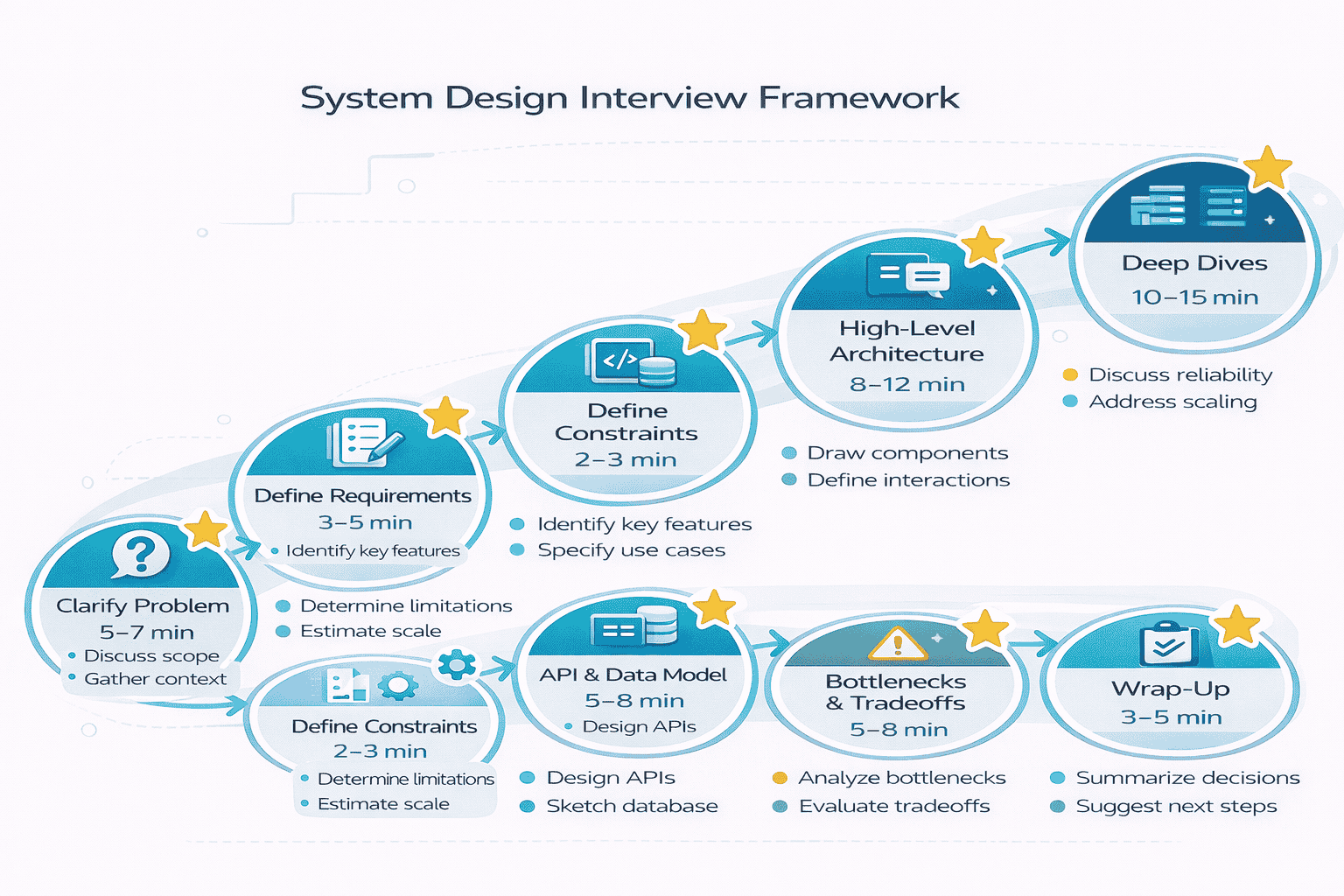
Phase 2: Define Functional Requirements (3-5 Minutes)
Based on your clarification conversation, explicitly state what the system must do. Write these down as a numbered list the interviewer can see.
Example for URL shortener: Based on our discussion here are the functional requirements 1 Users can submit long URLs and receive short URLs 2 When users click short…
State these confidently, then pause for confirmation. The interviewer might add requirements or remove some to narrow scope.
Phase 3: Define Non-Functional Requirements (2-3 Minutes)
These specify how well the system performs, not what it does. They drive architectural decisions more than functional requirements do.
Example continuation: For non-functional requirements 1 The system should handle 1000 URL creations per second and 10 000 redirects per second 2 Redirect latency must be under 100ms…
These numbers anchor every subsequent decision. You’ll reference them repeatedly when choosing technologies and architectures.
Phase 4: Define API and Data Model (5-8 Minutes)
Before drawing architecture boxes, define the contract. What APIs does the system expose? What data structures does it store?
API design example: We need two main APIs POST api urls with body originalUrl string customShortUrl string returns shortUrl string createdAt timestamp GET shortCode redirects to the original…
Keep API definitions lightweight—endpoint, HTTP method, key parameters, response. Don’t over-specify every field unless the interviewer asks.
Data model example: We’ll store URL mappings with fields shortCode string primary key originalUrl string createdAt timestamp clickCount integer userId optional foreign key if we add user accounts…
The data model reveals what you understand about the problem domain Including clickCount shows you thought about analytics Including userId shows you considered future extensibility even though it’s…
Phase 5: Present High-Level Architecture (8-12 Minutes)
Now draw the boxes. Start with the simplest architecture that meets requirements, then explain what each component does.
Initial architecture: At a high level we have a load balancer distributing traffic across multiple web servers The web servers handle API requests and interact with a primary…
Draw this clearly. Label components. Show data flow with arrows. This visual becomes your reference point for the rest of the interview.
Explain the read path: When a user clicks a short URL the request hits the load balancer routes to a web server checks Redis cache for the shortCode…
Explain the write path: URL creation hits the web server generates a unique short code using base62 encoding of an auto-incrementing ID writes to the primary database and…
Phase 6: Deep Dive Into 2-3 Components (10-15 Minutes)
The interviewer will guide this phase by asking about specific areas. If they don’t, proactively choose the most interesting components to explain in depth.
Deep dive example—short code generation: Let me explain how we generate unique short codes We’ll use an auto-incrementing database sequence to guarantee uniqueness We convert this integer…
This shows depth: you explained the approach, did the math, and discussed alternatives with their tradeoffs.
Deep dive example—caching strategy: For caching I’m using cache-aside pattern The application checks cache first then database on miss We choose cache-aside over write-through because our read…
Phase 7: Address Bottlenecks and Tradeoffs (5-8 Minutes)
Proactively identify where the system breaks at scale. Don’t wait for the interviewer to point out problems.
Bottleneck identification: At our target scale of 10 000 redirects per second the database becomes the bottleneck if cache hit rate drops We’re targeting 90 cache hit rate…
Scaling strategy: The web servers scale horizontally with no state We can add servers behind the load balancer as needed Redis can also scale horizontally using Redis Cluster…
Failure mode discussion: “Key failure modes: If Redis fails completely, all requests hit the database directly. We’ll implement circuit breakers and rate limiting to prevent overwhelming the database We’d also…
Phase 8: Wrap-Up and Follow-Ups (3-5 Minutes)
Use remaining time to address questions you anticipated or discuss extensions.
Proactive topics: If we had more time I’d discuss monitoring and observability specifically tracking cache hit rates database query latency and redirect response times I’d also cover our…
This shows you’re thinking beyond the immediate problem to operational concerns.
📥 Download: Interview Framework Checklist
A printable one-page checklist covering all eight phases with time allocations and key questions to ask yourself Use this during practice sessions to build muscle memory for the…
Download PDFHow to Adapt This Framework to Different Problem Types
This eight-phase structure works for any system design problem, but emphasis shifts based on problem category.
Data-intensive systems (analytics, logging): Spend more time on data model and storage strategy. Discuss partitioning, compression, and query patterns in depth. Scalability focuses on data volume growth.
User-facing systems (social networks, messaging): Emphasize latency requirements and user experience. Discuss caching strategies extensively. Reliability focuses on graceful degradation when components fail.
Infrastructure systems (rate limiters, load balancers): Focus on algorithmic choices and performance characteristics. Discuss concurrency and synchronization. Scalability emphasizes request throughput.
The framework phases stay the same, but you adjust time allocation based on what matters most for each problem category.
Core Building Blocks You Must Master
Every system design combines fundamental components. Understanding these building blocks—when to use them, their tradeoffs, and common pitfalls—lets you construct architectures quickly and confidently.
Caching Strategies and Patterns
Caching appears in nearly every system design interview. Master the core patterns and their tradeoffs.
Cache-aside (lazy loading): Application checks cache first On miss loads from database and populates cache Use when read-heavy workloads dominate and not all data deserves caching Tradeoff first…
Write-through: Application writes to cache and database simultaneously Use when data consistency is critical and you want cache always up-to-date Tradeoff slower writes dual write latency but reads…
Write-behind (write-back): Application writes to cache immediately asynchronously syncs to database later Use when write performance is critical and you can tolerate brief inconsistency risk Tradeoff fastest writes…
When to use caching: Read-heavy workloads (10:1 ratio or higher), expensive database queries, hot data that accounts for 80%+ of traffic, geographically distributed users needing low latency.
Message Queues and Event Streaming
Queues decouple components and handle asynchronous processing. Understand the distinction between message queues and streaming platforms.
Message queues (RabbitMQ, SQS): Point-to-point or pub-sub messaging where messages are consumed and deleted Use for task distribution asynchronous processing decoupling microservices Example email sending service consumes jobs…
Event streams (Kafka, Kinesis): Persistent log of events that multiple consumers can read independently Use for event sourcing real-time analytics feeding multiple downstream systems Example user activity stream…
When to use message queues: Smoothing traffic spikes, rate limiting expensive operations, ensuring tasks complete even if service restarts, priority-based processing. When to use streaming: Multiple teams need…
Database Selection Framework
The SQL versus NoSQL decision paralyzes many candidates. Use requirements to drive the choice systematically.
Choose SQL (PostgreSQL, MySQL) when: You need ACID transactions complex joins across tables strong consistency guarantees mature tooling and expertise on your team data relationships are core to…
Choose NoSQL when: You need horizontal scaling from day one schema flexibility for rapidly evolving data high write throughput data naturally partitions by key e g user ID…
Common pitfall choosing NoSQL because it scales better without understanding the consistency and query flexibility you’re sacrificing SQL databases scale to millions of queries per second with proper…
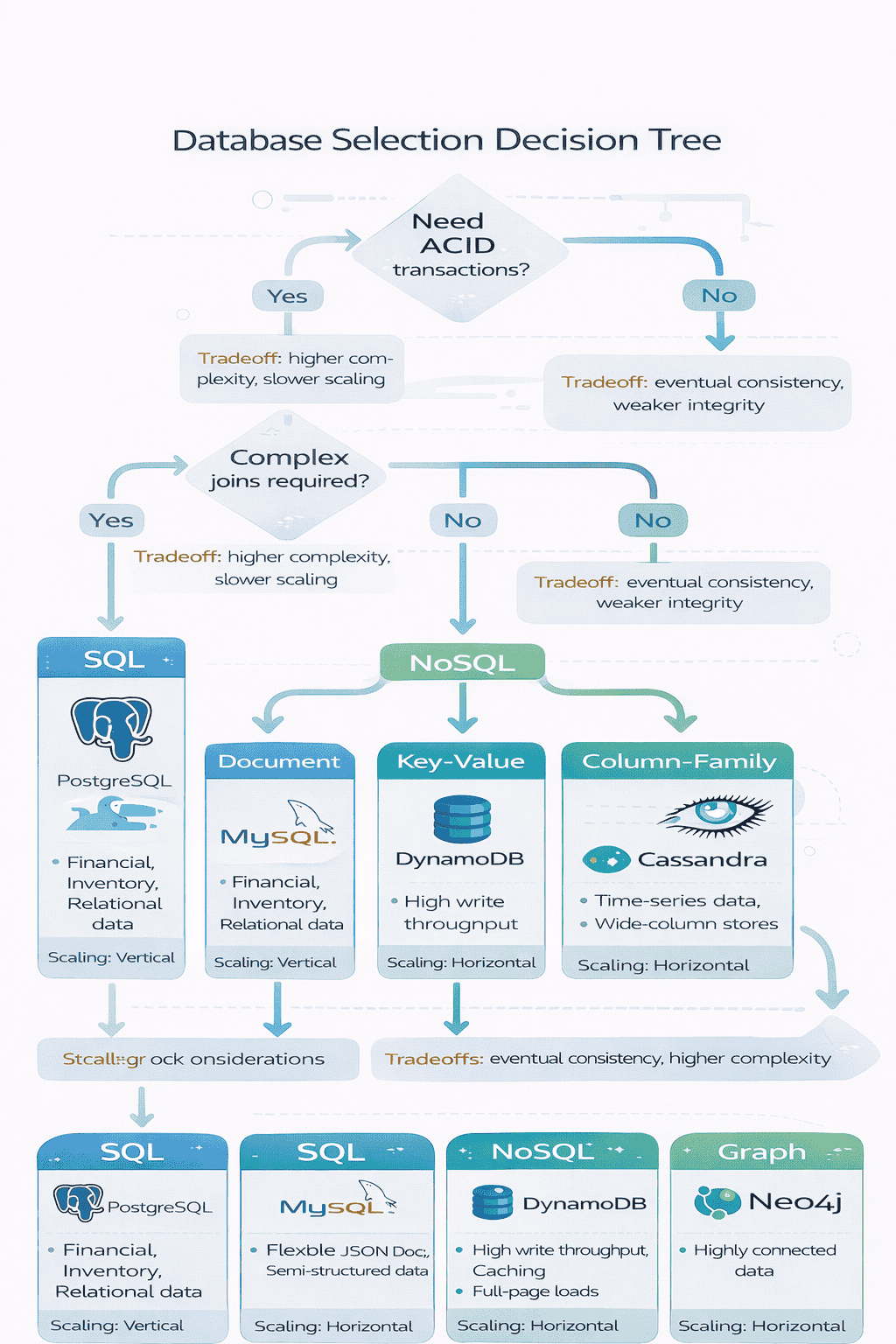
Load Balancing Strategies
Load balancers distribute traffic across servers. The algorithm choice affects performance and reliability.
Round-robin: Distribute requests sequentially across servers. Simple and works well when servers have equal capacity and requests have similar cost. Pitfall: long-running requests can imbalance load over time.
Least connections: Route to server with fewest active connections. Better for varying request durations. Tradeoff: requires tracking connection state, slightly more complex than round-robin.
Consistent hashing: Hash request attribute user ID session ID to determine server Use when session affinity matters or you’re distributing cache across servers Tradeoff uneven distribution if hash…
Layer 4 vs Layer 7 load balancing: Layer 4 transport layer operates on TCP UDP packets without inspecting content faster but less flexible Layer 7 application layer inspects…
Sharding and Partitioning
Sharding splits data across multiple databases to scale writes and storage. It introduces complexity—only implement when necessary.
Hash-based sharding: Hash the partition key e g user ID to determine shard Provides even distribution Pitfall rebalancing when adding shards is expensive use consistent hashing to minimize…
Range-based sharding: Partition by ranges e g users A-M on shard 1 N-Z on shard 2 Allows range queries within shards Pitfall uneven distribution if data isn’t uniformly…
Geographic sharding: Partition by region (US users on US shard, EU users on EU shard). Optimizes latency and data compliance. Pitfall: cross-region queries become complex and slow.
When to shard: Single database write throughput is exceeded, data volume exceeds single machine storage, latency requirements demand geographic distribution. When to avoid: You can still vertically scale…
Replication Patterns
Replication improves availability and read performance. Understand the consistency tradeoffs.
Primary-replica (master-slave): All writes go to primary replicas serve reads Asynchronous replication is common primary doesn’t wait for replica confirmation Use for read-heavy workloads where brief inconsistency is…
Synchronous replication: Primary waits for at least one replica to confirm write Guarantees consistency but slower writes Use when consistency is critical Tradeoff write latency increases availability risk…
Multi-primary (multi-master): Multiple nodes accept writes independently Complex conflict resolution required Use for geographically distributed writes or high availability Tradeoff conflicts must be resolved last-write-wins application-level resolution or…
Consistency Models You Must Explain
Interviewers frequently probe consistency understanding. Explain these clearly.
Strong consistency: Reads always return the most recent write All nodes see the same data at the same time Use when correctness depends on immediate visibility financial transactions…
Eventual consistency: Given enough time without new writes all nodes converge to the same value Reads may return stale data temporarily Use when performance matters more than immediate…
Read-after-write consistency: Users always see their own writes immediately but may see stale data from other users Use for better user experience in eventually consistent systems Implementation route…
Reliability & Production Thinking (What Most Candidates Miss)
Reliability separates candidates who have shipped production systems from those who only know textbook architectures Interviewers probe reliability thinking to predict whether you’ll build systems that actually work…
The SLO/SLI Mindset for Interviews
You don’t need to design full SRE programs in interviews, but demonstrating SLO thinking shows production maturity.
Service Level Indicators (SLIs): Measurable metrics that indicate system health For a web service request latency error rate throughput For a data pipeline processing lag data loss rate…
Service Level Objectives (SLOs): Target values for SLIs that define acceptable performance Connect SLOs to requirements Based on our 99 9 availability target we can tolerate 43 minutes…
This connection between availability numbers and architectural choices demonstrates understanding beyond surface-level knowledge.
Common Failure Modes and How to Address Them
Production systems fail in predictable ways. Discussing these proactively shows you’ve debugged real outages.
Partial outages: Not all servers fail simultaneously A subset becomes unhealthy creating uneven load distribution Solution Health checks at load balancer level automatically remove unhealthy instances from rotation…
Thundering herd: When cache expires or service restarts thousands of requests simultaneously hit the backend Solution Request coalescing multiple requests for same resource wait for single backend call…
Cascading failures: One component failure triggers failures in dependent components Database slowdown causes application servers to accumulate connections which exhausts thread pools which causes load balancer health checks…
Network partitions: Servers lose connectivity with each other but stay individually healthy In distributed databases this creates split-brain scenarios where multiple nodes think they’re primary Solution Consensus algorithms…
📊 Table: Failure Modes and Prevention Strategies
Memorize these failure modes and their solutions. Voluntarily mentioning 2-3 during your interview signals production experience and earns reliability points on the rubric.
| Failure Mode | What Happens | Prevention Strategy | Interview Signal |
|---|---|---|---|
| Partial Outage | Some servers fail, overload survivors | Active health checks + auto-removal | Shows operational awareness |
| Thundering Herd | Cache expiration floods database | Request coalescing + jittered TTLs | Demonstrates caching depth |
| Cascading Failure | One failure triggers chain reaction | Timeouts + bulkheads + circuit breakers | Understands blast radius control |
| Network Partition | Servers can’t communicate | Consensus protocols + CAP choices | Grasps distributed systems theory |
| Resource Exhaustion | Memory/connections/disk fills up | Rate limiting + backpressure + monitoring | Knows resource management |
| Slow Dependencies | External service delays propagate | Aggressive timeouts + fallbacks | Thinks about dependency risk |
Retry Logic and Exponential Backoff
Retries recover from transient failures but cause problems when implemented poorly. Explain your retry strategy clearly.
When to retry: Network timeouts, 5xx server errors (but not 500 Internal Server Error which might indicate bad request), rate limit responses (429). When not to retry: 4xx…
Exponential backoff with jitter: First retry after 100ms second after 200ms third after 400ms adding random jitter to prevent synchronized retries across clients In interviews explain the math…
Idempotency requirements: Retries only work safely for idempotent operations Creating a user account twice causes problems Solution Include idempotency keys with requests For payment processing clients would generate…
Circuit Breaker Pattern
Circuit breakers prevent cascading failures by stopping requests to failing dependencies.
Three states: Closed normal operation requests pass through Open failure threshold exceeded immediately reject requests Half-Open testing if service recovered allow limited requests Track failure rate over sliding…
Example explanation: We’d implement circuit breakers on our recommendation service calls If the service fails on 5 consecutive requests or 50 failure rate over 10 seconds the circuit…
This shows you understand the pattern and can explain concrete parameters.
Graceful Degradation Strategies
Systems should degrade gracefully rather than failing completely. Explain what functionality you preserve during outages.
Feature prioritization: Identify critical path versus nice-to-have features For an e-commerce site browsing and checkout are critical personalized recommendations are nice-to-have During recommendation service outage show popular items…
Stale data as fallback: Serving slightly stale data beats serving no data If our analytics service is down we’d serve yesterday’s dashboard from cache rather than showing error…
Read-only mode: When write path fails but read path works explicitly communicate system status During database primary failover we’d enter read-only mode for 30-60 seconds Users can browse…
Disaster Recovery Basics
DR discussions in interviews should stay high-level unless the interviewer probes deeper.
Recovery Time Objective (RTO): How long can you be down Connect to availability requirements Our 99 9 uptime allows 43 minutes downtime per month We’d target 5-minute RTO…
Recovery Point Objective (RPO): How much data can you lose Drive backup strategy For a financial system with zero data loss tolerance we need synchronous replication to standby…
Backup and restore: Mention automated backups and tested restore procedures We’d take daily database snapshots to S3 with 30-day retention More importantly we’d test restores monthly to verify…
Observability for Interviews
Production systems need monitoring. Briefly mention observability without derailing the interview.
Three pillars: Logs detailed event records for debugging Metrics time-series numerical data for alerting Traces request flow through distributed system In interviews We’d instrument our services with structured…
Key metrics to mention: Request rate error rate latency percentiles p50 p95 p99 saturation CPU memory disk network We’d alert on p95 latency exceeding 200ms or error rate…
Keep observability discussion concise unless the interviewer specifically asks about it. This shows you know production concerns without consuming precious interview time.
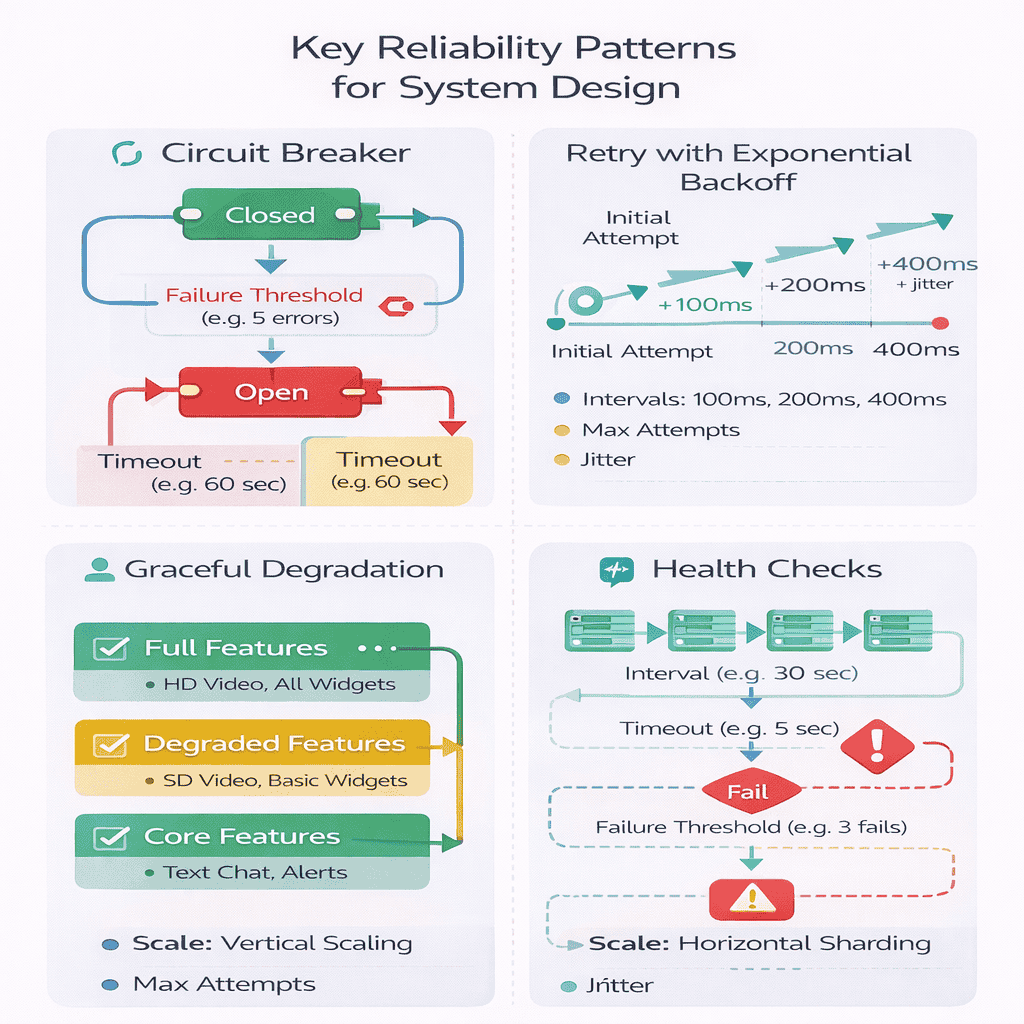
Security & Abuse Prevention (Interview-Ready Version)
Security discussions in system design interviews should demonstrate awareness without deep cryptographic details. Focus on practical security patterns relevant to the system you’re designing.
Authentication Versus Authorization
Clarify this distinction explicitly when security comes up. Many candidates confuse the two.
Authentication (AuthN): Proving identity Who are you Mechanisms include passwords OAuth tokens JWTs API keys In interviews Users authenticate via OAuth 2 0 with Google GitHub Upon successful…
Authorization (AuthZ): Determining permissions What can you do Mechanisms include role-based access control RBAC attribute-based access control ABAC access control lists ACLs In interviews We implement RBAC with…
Common pitfall: implementing authentication but forgetting authorization checks in API endpoints. Always mention both.
API Security Patterns
Secure API design prevents unauthorized access and abuse.
Token-based authentication: Stateless tokens JWT versus stateful sessions In interviews explain tradeoffs JWTs are stateless servers don’t need to store session data enabling horizontal scaling However revocation is…
HTTPS everywhere: Mention TLS for data in transit All API traffic uses HTTPS to prevent man-in-the-middle attacks We’d enforce HTTPS at load balancer level and configure HSTS headers…
Input validation: Never trust client input We’d validate all inputs server-side sanitize strings to prevent SQL injection limit size to prevent DoS via large payloads validate types and…
Data Privacy and Protection
Handling sensitive data requires explicit protection strategies.
Personally Identifiable Information (PII): Identify what data is sensitive In interviews Our system handles PII including names email addresses and payment information We’d implement field-level encryption for credit…
Encryption at rest: Protect stored data Database encryption at rest using native PostgreSQL encryption Encryption keys managed via AWS KMS with automatic rotation Application servers fetch decryption keys…
Encryption in transit: Already covered under HTTPS but mention it in data flow discussions Data flows from client load balancer app servers database all use TLS Internal service-to-service…
Lightweight Threat Modeling
Demonstrate security thinking without spending 20 minutes on threat analysis.
STRIDE framework (briefly): Spoofing authentication Tampering integrity Repudiation audit logs Information Disclosure encryption Denial of Service rate limiting Elevation of Privilege authorization In interviews pick 2-3 relevant threats…
Attack surface analysis: Identify where attackers might target your system Public API endpoints are our main attack surface We’d implement API gateway with authentication rate limiting and WAF…
Abuse Prevention and Rate Limiting
Systems need protection against malicious and excessive usage.
Rate limiting strategies: Prevent API abuse We’d implement tiered rate limits anonymous users 10 requests minute authenticated users 100 requests minute premium users 1000 requests minute Using token…
Explain the algorithm briefly Token bucket allows burst traffic users accumulate tokens over time and can spend multiple tokens for burst Compare to fixed window simple but allows…
Bot detection: Distinguish humans from bots For user-facing forms we’d implement CAPTCHA on suspicious traffic patterns detected via rate limiting and behavioral analysis For API clients we’d require…
DDoS mitigation: Protect against distributed denial of service We’d use CloudFlare or AWS Shield for L3 L4 DDoS protection they absorb volumetric attacks before traffic reaches our infrastructure…
📊 Table: Security Layers and Implementation
Security happens at multiple layers. This table shows where each protection mechanism fits and what it defends against. Use this to structure security discussions in your interviews.
| Layer | Security Mechanism | Protects Against | Interview Mention |
|---|---|---|---|
| Network | TLS/HTTPS, VPC, Firewall | Man-in-the-middle, unauthorized access | “All traffic uses HTTPS with TLS 1.3” |
| API Gateway | Authentication, Rate Limiting, WAF | Unauthorized requests, abuse, common attacks | “API gateway enforces OAuth + rate limits” |
| Application | Input validation, Authorization | SQL injection, XSS, privilege escalation | “Server-side validation + RBAC checks” |
| Data | Encryption at rest, Field-level encryption | Data breaches, insider threats | “PII encrypted with AES-256” |
| Monitoring | Audit logs, Anomaly detection | Breach detection, suspicious patterns | “Log all access with user attribution” |
Handling User-Generated Content
Systems accepting user content need protection against malicious uploads.
Content validation: Verify file types and sizes For image uploads we’d validate file type via magic bytes not just extension which users can fake limit size to 5MB…
Storage isolation: Don’t serve user content from your application domain User uploads stored in separate S3 bucket with its own domain This prevents XSS attacks where malicious JavaScript…
Content sanitization: Strip dangerous content For text input allowing HTML we’d use libraries like DOMPurify to strip script tags event handlers and dangerous attributes For markdown render server-side…
Spam and Fraud Prevention
Mention anti-spam strategies relevant to your system design.
Account creation abuse: Prevent fake account floods Implement CAPTCHA on signup require email verification and rate limit account creation per IP address We’d also implement phone verification for…
Content spam: Detect and filter spam content For user comments or posts we’d implement keyword-based filtering for known spam patterns rate limit post creation and flag suspicious patterns…
Payment fraud: If handling payments mention fraud signals We’d track user behavior patterns new accounts making large purchases trigger manual review mismatched shipping billing addresses raise fraud score…
When Security Discussions Go Too Deep
Recognize when security discussion consumes too much time. Most interviewers want awareness, not cryptographic expertise.
Signal understanding, then move on: For encryption we’d use industry-standard AES-256 for data at rest and TLS 1 3 for data in transit with key management via AWS…
This shows knowledge while giving the interviewer choice to redirect If they say that’s sufficient you’ve satisfied security concerns efficiently If they want more depth they’ll ask specific…
Frequently Asked Questions
Ready to Transform Your Interview Performance?
This guide gives you the framework. geekmerit.com gives you the structured coaching, mock interview practice, and personalized feedback to execute it flawlessly.
What 2,400+ Senior Engineers Learned:
- ✓ 10 structured modules covering requirements clarification through advanced scaling patterns
- ✓ 200+ practice problems with detailed solutions showing multiple valid approaches
- ✓ 12 mock interview videos breaking down real sessions with L5+ candidates
- ✓ Live 1-on-1 coaching (Guided and Bootcamp plans) with personalized feedback on your weak areas
- ✓ 94% success rate landing offers at target companies within 3 months
Three plans designed for different learning styles:
Self-Paced
$197
All materials, lifetime access
Guided
$397
+ 3 coaching sessions
Bootcamp
$697
+ 8 sessions + 3 mocks
30-day money-back guarantee • Lifetime access • No hidden fees
Not ready to enroll? Try a free mock interview first:
Experience Our Mock Interview Process →Citations
- https://github.com/donnemartin/system-design-primer
- https://interviewing.io/guides/system-design-interview
- https://www.educative.io/courses/grokking-the-system-design-interview
- https://landing.google.com/sre/sre-book/toc/
- https://www.palantir.com/docs/gotham/overview/
- https://aws.amazon.com/architecture/well-architected/
- https://martinfowler.com/articles/patterns-of-distributed-systems/
- https://redis.io/topics/introduction
- https://kafka.apache.org/documentation/
Content Integrity Note
This guide was written with AI assistance and then edited, fact-checked, and aligned to expert-approved teaching standards by Andrew Williams . Andrew has over 10 years of experience coaching software developers through technical interviews at top-tier companies including FAANG and leading enterprise organizations. His background includes conducting 500+ mock system design interviews and helping engineers successfully transition into senior, staff, and principal roles. Technical content regarding distributed systems, architecture patterns, and interview evaluation criteria is sourced from industry-standard references including engineering blogs from Netflix, Uber, and Slack, cloud provider architecture documentation from AWS, Google Cloud, and Microsoft Azure, and authoritative texts on distributed systems design.

