Design a URL Shortener System: The Complete System Design Interview Guide
You walk into the interview room. The interviewer says, “Let’s design a URL shortener system Your heart races Do they want TinyURL Bitly A complete production system Within…
Most senior engineers fail URL shortener interviews not because they lack technical skills but because they treat it like a coding problem instead of a structured conversation They…
This guide walks you through the exact interview framework that successful candidates use to ace URL shortener system design questions You’ll see how strong answers are structured why…
Last updated: Feb. 2026
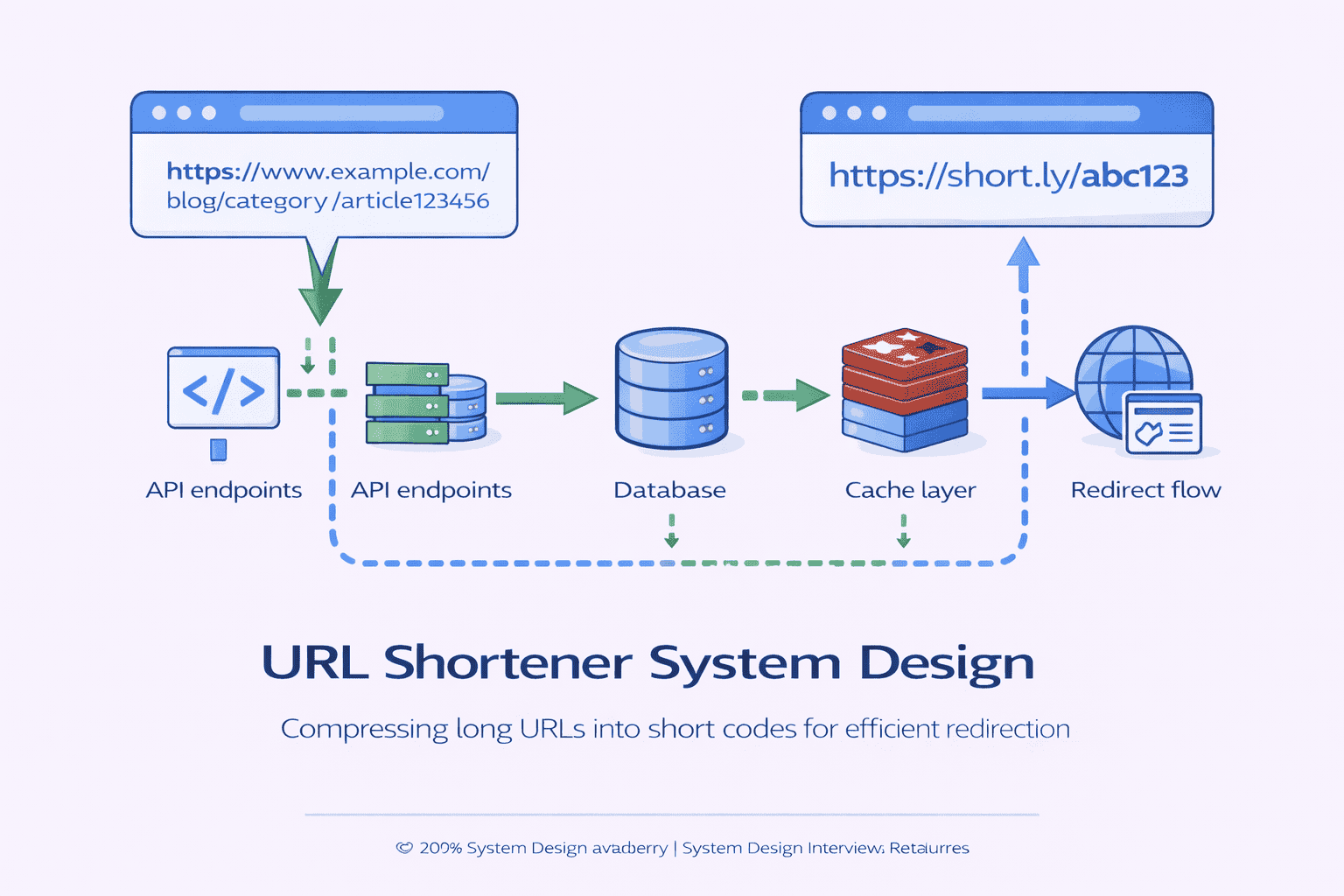
Table of Contents
- 1. Understanding What the Interviewer Actually Tests
- 2. Requirement Clarification: The Interview Starting Point
- 3. API Design Before Architecture
- 4. High-Level Architecture Walkthrough
- 5. Database Schema and Data Modeling
- 6. Scaling Strategy: The Interview Depth Zone
- 7. Caching and Performance Optimization
- 8. Rate Limiting, Abuse Prevention, and Reliability
- 9. Trade-Offs and Design Justification
- 10. Closing the Interview Strong
- 11. FAQs
Contents
Understanding What the Interviewer Actually Tests
The URL shortener problem is deceptively simple At first glance it seems straightforward take a long URL generate a short code store the mapping redirect users But that’s…
System design interviews don’t test your ability to build software. They test your ability to think systematically communicate clearly and make informed engineering decisions under ambiguity The URL shortener is just…
Here’s what strong candidates understand that struggling candidates miss:
The Five Core Skills Being Evaluated
1. Requirement Clarification Can you ask the right questions before diving into solutions Do you understand the difference between functional requirements what the system does and non-functional requirements…
Weak candidates immediately start drawing boxes and arrows Strong candidates spend 3-5 minutes clarifying scope constraints and success criteria This isn’t wasted time it’s the foundation that prevents…
2. System Decomposition — Can you break a complex system into clear, logical components? Do you think in layers: API, application logic, data storage, caching?
The interviewer wants to see architectural thinking. They’re watching how you organize complexity, not whether you memorize specific technologies.
3. Trade-Off Analysis — Can you articulate why you chose approach A over approach B? Do you understand the cost-benefit dynamics of your decisions?
Every design choice has trade-offs SQL versus NoSQL Consistent hashing versus range-based partitioning Pre-generating IDs versus generating on-demand Strong candidates verbalize these trade-offs proactively Weak candidates make choices…
4. Scalability Reasoning — Can you think about systems under load? Do you understand when optimizations become necessary?
This isn’t about memorizing use a CDN or add more caches It’s about understanding growth patterns bottleneck identification and incremental scaling strategies The interviewer will push you What…
5. Communication and Adaptation — Can you explain your thinking clearly? Do you respond to interviewer signals and adjust your design?
The best technical design in the world fails if you can’t articulate it Conversely a decent design explained clearly with visible reasoning and responsiveness to feedback often scores…
Why Senior Engineers Struggle With “Simple” Problems
You might have 10 years of experience building production systems You’ve shipped microservices handling millions of requests You’ve debugged distributed transactions at 3 AM Yet you walk into…
If this gap comes from not having formal architecture/design exposure yet, see: How to Crack System Design Interviews Without Prior Design Experience.
This disconnect happens because real-world engineering and interview engineering are different contexts.
In production, you have time. You research solutions, run proof-of-concepts, discuss with teammates. Requirements evolve over weeks. You iterate based on metrics.
In interviews you have 45 minutes Requirements are intentionally vague There’s no Stack Overflow no existing codebase to reference The interviewer wants to see how you navigate this…
Senior engineers often fail because they apply production-engineering instincts to an interview context They want to get it right They overthink edge cases They design for requirements that…
The interview is not about perfection. It’s about process.
To choose a preparation approach (course vs DIY), read: System Design Course vs Self-Study – What Works for Senior Developers?.
📊 Table: Production Engineering vs. Interview Engineering
Understanding this fundamental difference changes how you prepare for and approach system design interviews. Production skills matter, but interview contexts require adapted communication and decision-making patterns.
| Dimension | Production Engineering | Interview Engineering |
|---|---|---|
| Time Horizon | Weeks to months | 45 minutes |
| Requirements | Detailed specs, evolving feedback | Intentionally ambiguous, static |
| Resources | Team collaboration, documentation, testing | Whiteboard, interviewer as only resource |
| Success Metric | System works in production | Clear communication of thought process |
| Iteration | Build, measure, iterate based on data | Design once, adapt based on verbal feedback |
| Depth Required | Implementation-level detail | Conceptual understanding with selective depth |
The Interview Framework Successful Candidates Use
After conducting 150+ mock system design interviews , I’ve identified a consistent pattern in successful candidates. They follow a structured approach that aligns with what interviewers want to see:
Step 1: Clarify requirements (5 minutes) — Ask about functional scope, scale, latency expectations, and acceptable trade-offs.
Step 2: Design the API (3 minutes) — Define the contract before discussing implementation. This forces clarity about what the system actually does.
Step 3: Sketch high-level architecture (5 minutes) — Draw major components and data flow. Keep it simple initially.
Step 4: Dive into data modeling (5 minutes) — Show how you’ll store and retrieve data. Justify storage choices.
Step 5: Address scalability (10-15 minutes) — This is where interviewers probe deepest. Discuss partitioning, replication, caching, and bottleneck mitigation.
Step 6: Handle production concerns (5-10 minutes) — Cover monitoring, rate limiting, failure handling, and abuse prevention.
Step 7: Summarize and extend (5 minutes) — Recap your design, acknowledge limitations, discuss how it could evolve.
This structure isn’t rigid Good interviewers will guide you through it organically But having this mental framework prevents you from jumping randomly between topics or spending 30 minutes…
The rest of this guide walks through each step in detail showing you exactly how strong candidates structure their answers what they say out loud and how they…
This isn’t theory. It’s the practical framework I teach in live system design coaching sessions with senior engineers preparing for FAANG interviews. The patterns you’ll see here are what gets candidates hired.
Requirement Clarification: The Interview Starting Point
Most candidates panic when the interviewer says design a URL shortener and immediately start drawing databases This is a critical mistake The first 3-5 minutes of requirement clarification…
Strong candidates start by asking questions, not proposing solutions.
What to Clarify First: Functional Requirements
Functional requirements define what the system does. For a URL shortener, the core functionality seems obvious, but there are many variants. You need to establish scope explicitly.
Here’s how a strong candidate opens this conversation:
“Before we dive into design, I’d like to clarify the requirements For the core functionality I’m assuming we need two main operations first users should be able to submit a long…
The interviewer will typically confirm this or add constraints. Then you can probe optional features:
Custom Aliases — Should users be able to choose their own short code, like bit.ly/my-campaign, or is it always system-generated?
This matters because custom aliases require collision detection and availability checking. System-generated IDs are simpler but less flexible.
Expiration — Do short URLs expire after a certain period, or are they permanent?
Expiration adds complexity (TTL tracking, cleanup jobs) but also reduces storage growth and handles abuse better.
Analytics — Do we need to track click counts, geographic data, or referral sources?
Analytics changes data modeling significantly. You’ll need event streams, aggregation pipelines, potentially a separate analytics database.
Authentication — Is this a public service where anyone can create short URLs, or does it require user accounts?
Authentication adds user management, authorization checks, and potentially quota enforcement per user.
For interview purposes, you usually want to keep the scope minimal initially. A strong response:
Got it To keep things focused let’s start with the core functionality system-generated short codes permanent storage no analytics and public access We can discuss extensions like custom…
This shows you can prioritize. You’re not avoiding complexity; you’re deferring it strategically so you can build a solid foundation first.
What to Clarify Next: Non-Functional Requirements
Non-functional requirements define how well the system performs. This is where you demonstrate understanding of production systems versus toy projects.
Scale — How many URL shortening requests per second? How many redirects? What’s the read-to-write ratio?
A typical interview assumption URL creation is infrequent maybe 1000 requests sec but redirects are heavy 100 000 requests sec or more This 100 1 read-to-write ratio shapes…
You might say: For scale I’m assuming we’re looking at around 1000 new URL creations per second but significantly higher redirect traffic maybe 100 1 ratio Does that…
Latency — How fast do redirects need to be? What about URL creation?
Redirects are user-facing, so sub-100ms latency is critical. URL creation can tolerate 200-500ms since it’s typically a one-time operation per campaign or link.
Availability — How important is uptime? Can we afford occasional downtime?
For a URL shortener used in marketing campaigns or critical workflows, high availability (99.99%+) is expected. This drives replication and failover strategies.
Durability — Can we ever lose URL mappings?
This is non-negotiable. Once a short URL is created, it must permanently map to the original URL. Data loss is unacceptable. This informs database choices and backup strategies.
Here’s how you might synthesize this:
So to summarize the non-functional requirements we need high availability for redirects sub-100ms latency on the read path and absolute durability we cannot lose URL mappings Write throughput…
This 30-second summary shows the interviewer you’ve internalized the requirements and are ready to design accordingly.
API Design Before Architecture
Before drawing boxes and arrows, define your API. This forces clarity about what your system actually does and creates a contract that shapes everything else.
Many candidates skip this step and jump straight to architecture diagrams They end up with vague designs because they never explicitly stated what endpoints exist what inputs they…
Strong candidates start with the API because it’s the clearest way to communicate system behavior.
The Two Core Endpoints
Based on our clarified requirements, we need exactly two API operations:
1. Create Short URL (Write Operation)
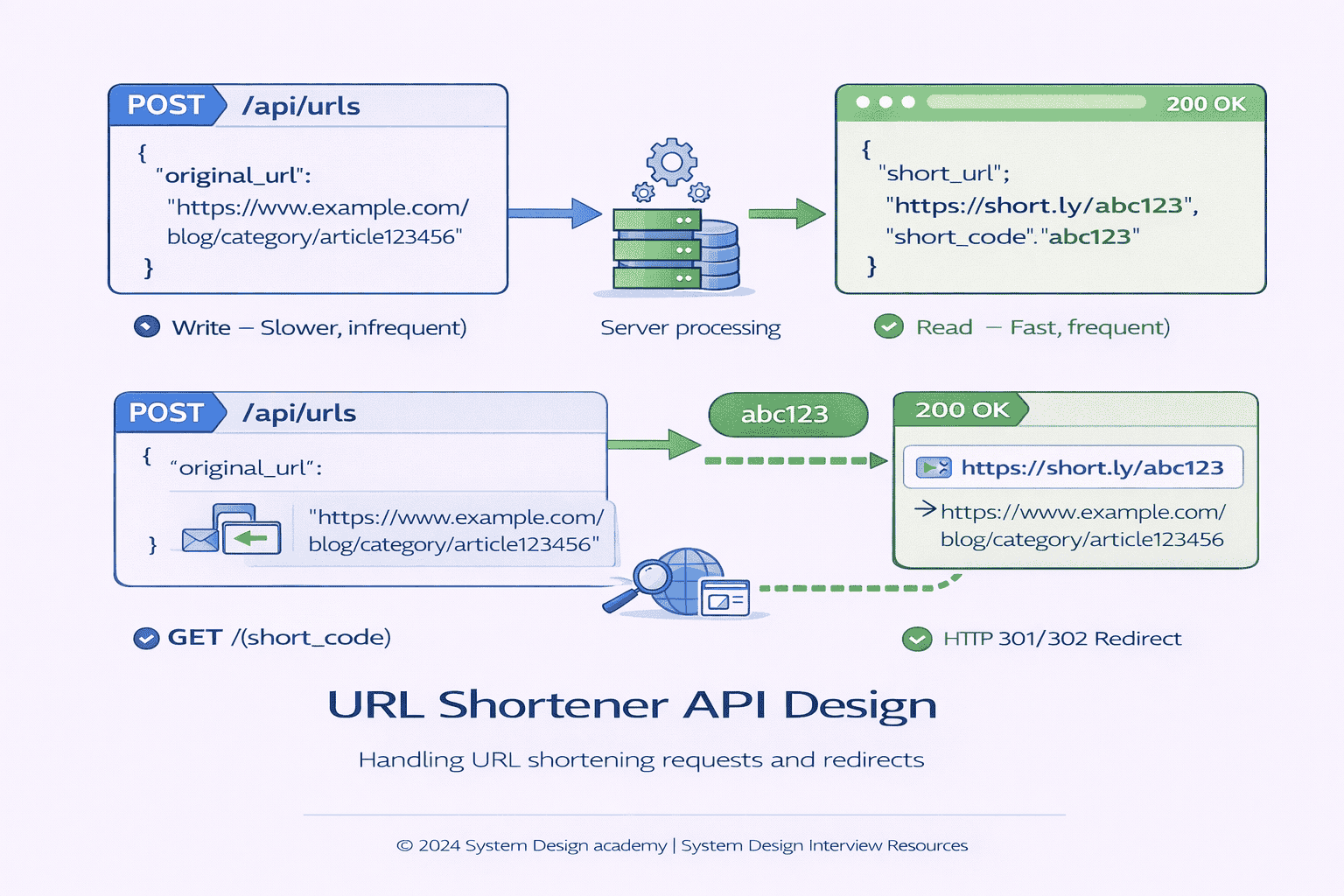
This endpoint accepts a long URL and returns a shortened version. Here’s how you might present it in the interview:
“For URL creation, I’m proposing a POST endpoint. The client sends the original URL, and we return the shortened version. Something like this:”
POST /api/urls
Request:
{ "original_url": "https://example.com/very/long/path" }
Response:
{ "short_url": "https://short.ly/abc123", "short_code": "abc123" }
Notice what you’re communicating here You’ve made several implicit decisions the endpoint is RESTful it returns both the full short URL and the code separately useful for different…
You should also mention error cases: If the URL is invalid or already exists we’ll return appropriate error codes 400 for malformed requests potentially 200 with the existing…
2. Redirect to Original URL (Read Operation)
This is where users actually click shortened links. The API design here is critical because it needs to be fast and simple:
For redirects I’m using a simple GET request where the short code is in the path When someone visits the short URL we look up the original and…
GET /{short_code}
Response:
HTTP 301 Redirect to original_url
This is where you can discuss an important trade-off. Should you use HTTP 301 (permanent redirect) or 302 (temporary redirect)?
HTTP 301 means this resource has permanently moved Browsers and CDNs cache this aggressively If you use 301 subsequent clicks might not even hit your servers the browser…
Pro: Extremely fast for repeat visitors. Reduces server load.
Con: You lose analytics visibility. Can’t track clicks after the first one per browser.
HTTP 302 means “this resource is temporarily elsewhere.” Browsers typically don’t cache these as aggressively.
Pro: Every click hits your servers, enabling analytics.
Con: Slightly slower, higher server load.
In the interview, you’d say: I’m using 301 for now since we’re not tracking analytics If that becomes a requirement we’d switch to 302 to ensure every click…
This shows you understand HTTP semantics and can reason about trade-offs.
What About Optional Features?
If the interviewer wants to explore extensions, you can quickly sketch additional endpoints:
Custom Aliases:
Add an optional field to the create request:
POST /api/urls
{ "original_url": "...", "custom_alias": "my-campaign" }
You’d need to validate uniqueness and handle collisions.
URL Deletion/Update:
DELETE /api/urls/{short_code}
PUT /api/urls/{short_code}
with new destination
These raise questions about ownership and authentication—who can delete a URL?
Analytics:
GET /api/urls/{short_code}/stats
Returns click count, geographic distribution, referrers.
Keep these brief unless the interviewer signals they want to dive deeper. The point is showing you can extend the design logically, not specifying every detail.
High-Level Architecture Walkthrough
Now that you’ve defined what the system does API you can sketch how it does it architecture This is where most candidates feel comfortable drawing boxes and arrows…
Wrong way: Draw everything at once. Throw in load balancers, message queues, caching layers, CDNs, databases, without explaining the flow or rationale.
Right way: Build the architecture incrementally. Start simple. Explain data flow. Add components one at a time, justifying each addition.
Starting Simple: The Minimal System
Begin with the absolute minimum to make the system work:
“Let me start with the simplest architecture that satisfies our requirements. We need three core components:”
1. API Layer / Web Server — Handles HTTP requests. Exposes the POST and GET endpoints we defined. This is your application tier.
2. Short URL Generation Service — Takes a long URL and produces a unique short code. This is your core business logic.
3. Database — Stores the mapping from short codes to original URLs. This is your persistence layer.
Walk through the flow for each operation:
URL Creation Flow:
1. Client sends POST request with original URL
2. API server receives request
3. Generation service creates unique short code
4 Store mapping short_code original_url…
Redirect Flow:
1. Client visits short URL
2. API server extracts short code from path
3. Query database for original URL
4 Return HTTP 301 redirect to original…
This simple architecture works. It’s not scalable yet, but it’s correct. Always start here before adding complexity.
Adding Scale: Load Balancing and Horizontal Scaling
The interviewer will push: “What if we have thousands of requests per second?”
This is your cue to discuss horizontal scaling:
At high load a single web server becomes a bottleneck We’ll add a load balancer in front of multiple API servers The load balancer distributes requests across a…
Key point: your API servers must be stateless No session data stored locally All state lives in the database or cache This makes horizontal scaling trivial every server…
Adding Speed: Caching Layer
Remember our read-heavy workload? 100 redirects for every 1 URL creation? Database queries on every redirect won’t scale.
Since redirects vastly outnumber creations we’ll add a caching layer Redis or Memcached between the API servers and database When a redirect request comes in we check the…
This is a standard read-through cache pattern . You should mention cache eviction policy (LRU is common) and TTL strategy (do cached entries expire?).
For a URL shortener cache TTL can be very long days or even indefinite because URL mappings rarely change This gives you extremely high cache hit rates maybe…
The Complete High-Level Architecture
Now you can present the full picture:
Client Layer:
Web browsers, mobile apps, any HTTP client
↓
Load Balancer:
Distributes traffic across API servers
↓
API Servers (Stateless):
Multiple instances handling requests in parallel
↓
Cache Layer (Redis):
Additionally, you have:
Short Code Generation Service: This might be embedded in the API servers or a separate microservice, depending on complexity.
In an interview, you don’t need to draw perfectly. Rough boxes and arrows work fine. What matters is narrating the data flow clearly and explaining why each component…
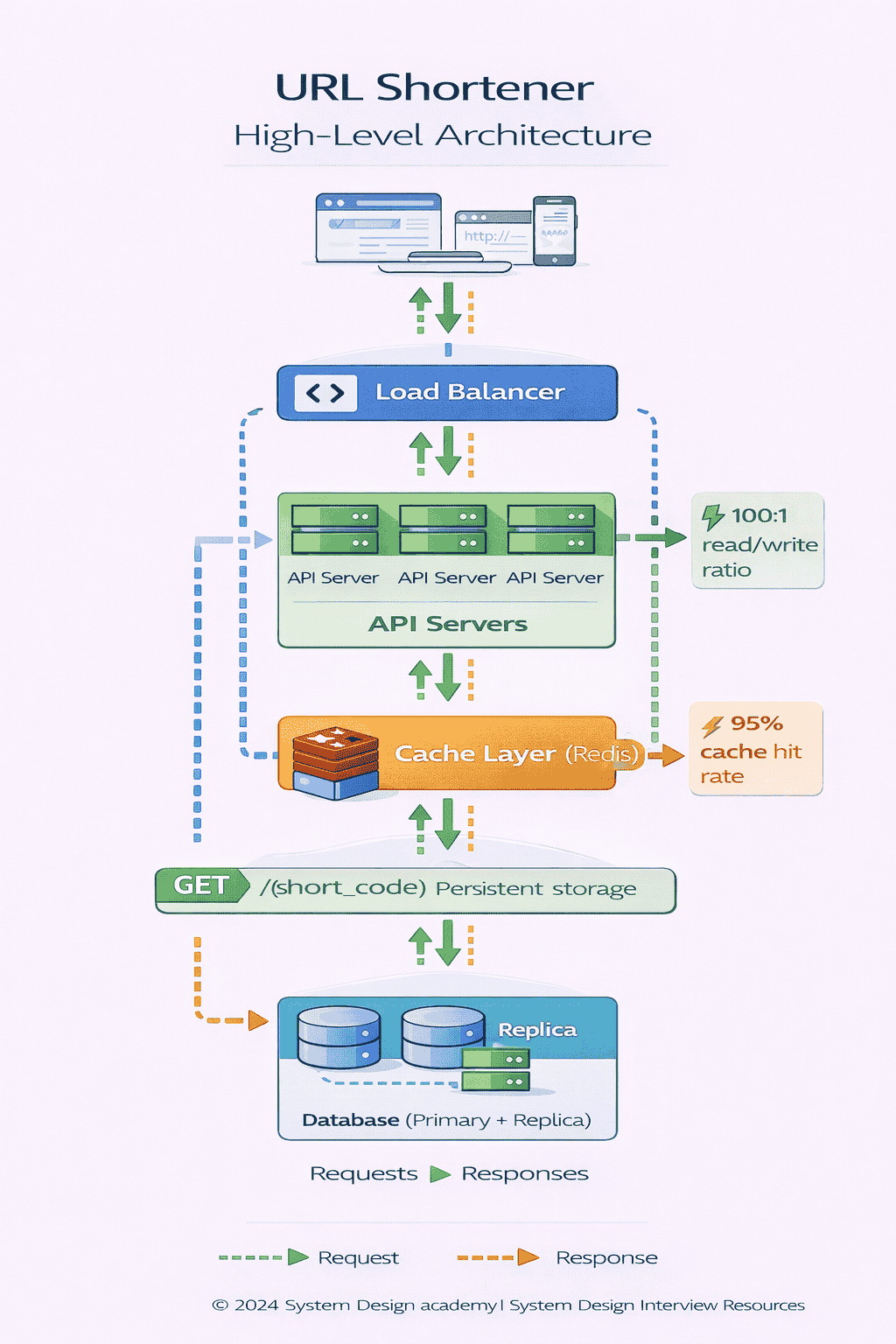
At this point in the interview you’ve established a solid foundation You have a working system that can scale horizontally and handle high read throughput The interviewer will…
If you want to master this level of architectural thinking across multiple system design problems—not just URL shorteners—our comprehensive curriculum walks through 40 different system design scenarios with…
Database Schema and Data Modeling
The interviewer will eventually ask How are you storing this data This is where candidates often overcomplicate or oversimplify The goal is finding the right level of detail…
The Core Schema: Minimal and Sufficient
For our basic URL shortener, the schema is remarkably simple. You need one table (or collection, if using NoSQL):
Table: url_mappings
-
short_code(string, primary key) — The unique identifier, e.g., “abc123” -
original_url(string) — The full destination URL -
created_at(timestamp) — When this mapping was created -
expires_at(timestamp, nullable) — Optional expiration time
That’s it for the minimum viable schema. Notice what we’re optimizing for:
Primary key on short_code
because that’s our lookup key. Every redirect query is:
SELECT original_url FROM url_mappings WHERE short_code = ?
This needs to be fast. With short_code as primary key, it’s an O(1) lookup via index.
No additional indexes initially because we’re not querying by anything other than short_code. Adding indexes without query patterns is premature optimization.
Extended Schema: Adding Features
If the interviewer asks about analytics or user management, you can extend the schema incrementally:
For user ownership:
Add
user_id
(foreign key) to track who created each URL
Add
users
table with account information
For analytics:
Add
click_count
(integer) for simple counting
Or create separate
clicks
table for detailed event tracking:
–
short_code
(foreign key)
–
timestamp
–
ip_address
–
user_agent
–
referrer
But don’t add these unless asked. Keep the core schema simple.
SQL vs NoSQL: The Database Choice
This is a common interview question: “Why did you choose SQL/NoSQL?”
The honest answer: both work fine for a URL shortener . The system’s access pattern (primary key lookups) suits both relational and NoSQL databases equally well.
Here’s how to discuss the trade-off intelligently:
Case for SQL (PostgreSQL, MySQL):
We could use a traditional relational database The schema is simple and unlikely to change frequently SQL gives us ACID guarantees which ensure we never lose URL mappings…
SQL also supports secondary queries easily. If you later want to query by user_id or created_at, adding indexes is straightforward.
Case for NoSQL (DynamoDB, Cassandra):
Alternatively we could use a NoSQL database like DynamoDB Our access pattern is simple always query by short_code NoSQL databases excel at single-key lookups and scale horizontally very…
NoSQL also handles write-heavy scenarios well if we later add heavy analytics writes (logging every click event).
The interviewer-friendly answer:
I’d probably start with PostgreSQL for simplicity and strong consistency guarantees As we scale if the database becomes a bottleneck we can either shard it ourselves or migrate…
This shows pragmatism. You’re not dogmatic about SQL vs NoSQL. You recognize both are viable and the choice depends on operational preferences and team expertise.
📊 Table: SQL vs NoSQL for URL Shortener
Both database paradigms work well for URL shortener workloads. The choice often comes down to operational considerations and team familiarity rather than technical capability.
| Consideration | SQL (PostgreSQL/MySQL) | NoSQL (DynamoDB/Cassandra) |
|---|---|---|
| Primary Key Lookups | Excellent (indexed) | Excellent (native) |
| Consistency | Strong ACID guarantees | Eventual consistency (configurable) |
| Horizontal Scaling | Manual sharding required | Automatic, transparent sharding |
| Schema Flexibility | Fixed schema, migrations needed | Schemaless, flexible evolution |
| Secondary Queries | Easy (add indexes) | Requires design-time planning |
| Operational Complexity | Well-understood, mature tooling | Simpler scaling, vendor lock-in |
| Cost at Scale | Predictable, instance-based | Pay-per-request, can spike |
Data Access Patterns: Optimizing for Reads
Remember: this system is 100:1 read-heavy. Design your data layer accordingly.
Writes (URL creation): Infrequent, can tolerate 200-500ms latency. We insert one row. Database handles this easily even at 1000 writes/second.
Reads (redirects): Constant, must be sub-100ms. At 100,000 reads/second, the database would be crushed without caching.
This is why our architecture includes Redis in front of the database Cache hit rate of 95 means only 5 000 database queries per second instead of 100…
If the interviewer asks about cache invalidation: Since URL mappings are immutable once created we don’t need to invalidate cache entries If we add URL updates or deletions…
Simple, correct reasoning based on the access pattern you established earlier.
Scaling Strategy: The Interview Depth Zone
This is where interviewers spend the most time. They want to see if you can think beyond “add more servers” and reason about distributed systems trade-offs at scale.
The key is building your scaling strategy incrementally. Don’t jump to “we need 1000 database shards” immediately. Show how the system evolves as load increases.
Identifying the Bottleneck: Database Writes
At some scale, your single database becomes the bottleneck. Let’s quantify when this happens.
A well-tuned PostgreSQL instance can handle roughly 10 000-15 000 writes per second on modern hardware If you’re at 1 000 URL creations per second you’re fine But…
“Once we exceed the write capacity of a single database instance, we need to partition the data across multiple databases. This is called sharding or horizontal partitioning.”
But here’s where many candidates stumble. They say “we’ll shard the database” without explaining how . The interviewer will push: “How do you decide which shard stores which URL?”
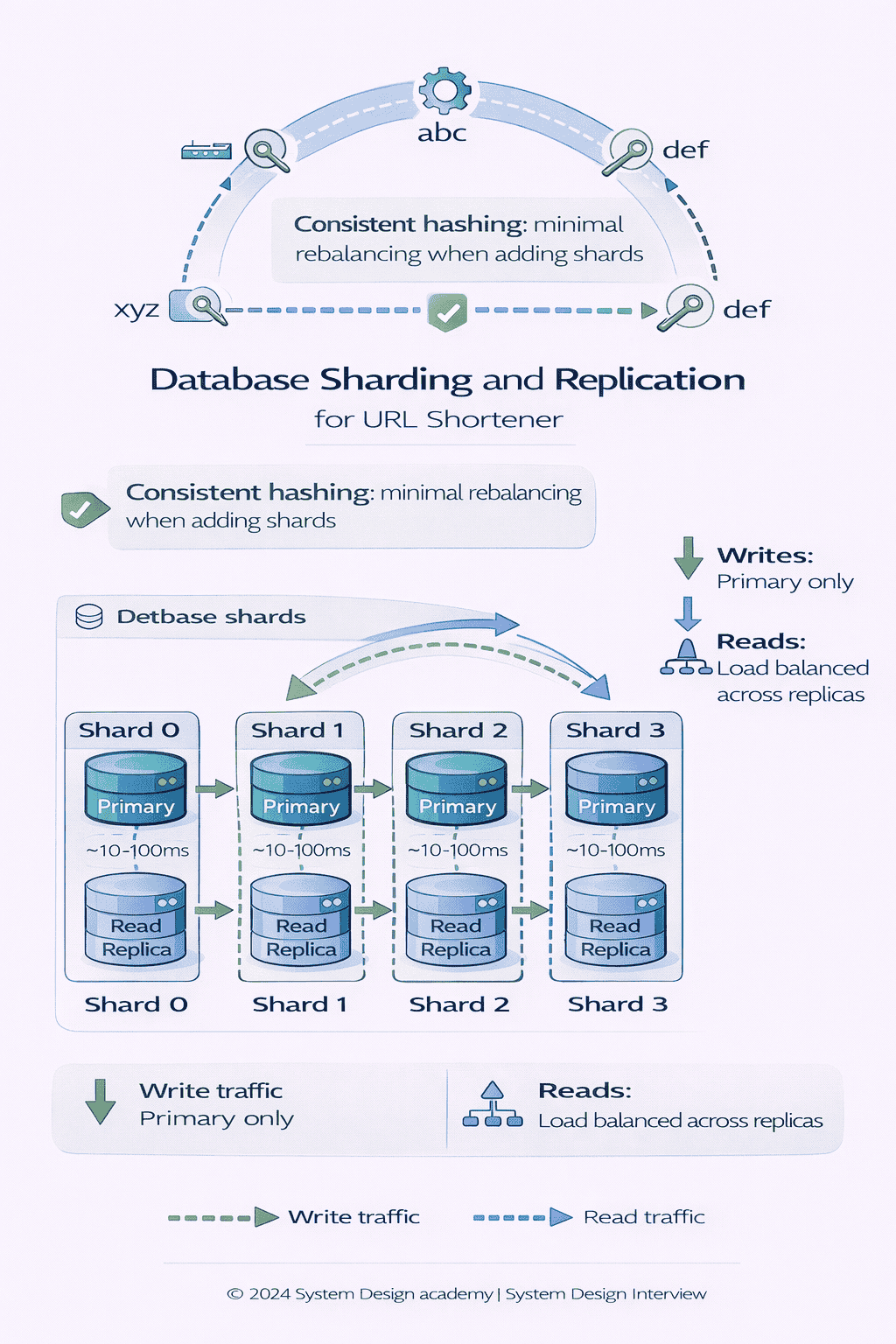
Sharding Strategy: Hash-Based Partitioning
You need a deterministic way to map short codes to database shards. The most common approach: hash-based partitioning .
We’ll use consistent hashing on the short_code to determine which shard stores each URL For example with 8 shards we compute hash short_code 8 to get the shard…
Why this works: Hashing distributes keys uniformly across shards. Each shard gets roughly 1/N of the total traffic.
The challenge: Adding or removing shards requires rebalancing data. If you go from 8 shards to 16, most keys need to move (because hash % 16 ≠ hash % 8).
The solution: We can use consistent hashing instead of simple modulo hashing Consistent hashing minimizes data movement when we add shards only about 1 N of the data…
You don’t need to implement consistent hashing on a whiteboard. Just showing you know it exists and why it’s better than naive modulo hashing is sufficient.
Database Reads: Replication Strategy
Even with caching 95 hit rate you’re still handling 5 000 database reads per second at 100K redirects sec A single database can handle this but what about…
For read scalability and high availability we’ll use database replication We have one primary database that handles all writes and multiple read replicas that serve read traffic If…
Read replicas scale reads horizontally. With 5 replicas, each handles ~1,000 queries per second instead of 5,000.
Replication lag: Replicas are eventually consistent. A URL created on the primary might not be visible on replicas for 10-100 milliseconds.
Is this a problem Usually not The cache sits in front of everything When you create a URL you can immediately populate the cache Subsequent redirect requests hit…
If the interviewer asks about this edge case, you can say: We can route reads to the primary for a short window after creation or accept that a…
Handling Hot Keys: The Viral Link Problem
The interviewer might throw a curveball: “What if one URL goes viral and gets 10 million redirects per hour?”
This is the hot key problem. Even with caching, a single short code might generate so much traffic that it overwhelms cache infrastructure or causes uneven load distribution.
Your response:
For extremely hot keys the cache layer handles most traffic Redis can serve millions of reads per second for a single key But if one URL is so…
1. CDN-based redirection: For predictable viral links (marketing campaigns), we can configure a CDN to handle redirects directly without hitting our infrastructure. The CDN caches the redirect response.
2. Multi-tier caching: Add an application-level cache (in-memory within each API server) above Redis. Hot keys stay in local memory, reducing Redis load.
3. Rate limiting per short code: If we detect abuse (someone hammering one URL with bots), we can rate-limit requests per short code.
This shows you can think about edge cases and have multiple mitigation strategies, not just one answer.
Geographic Distribution: Global Scale
If the interviewer asks about serving global users: “How would you handle users in Asia, Europe, and North America?”
This opens discussion of geographic distribution:
Read path (redirects): Deploy API servers and cache clusters in multiple regions Users hit the nearest region via DNS-based geo-routing Each regional cache holds popular URLs Cache misses…
Write path (URL creation): Writes can go to a single primary region. 200-500ms write latency is acceptable, so cross-region latency doesn’t hurt user experience.
Alternative: Multi-region active-active writes with conflict resolution. More complex, only necessary at extreme scale. For most URL shorteners, single-region writes with multi-region reads is sufficient.
At this point you’ve covered the major scaling dimensions sharding for write throughput replication for read availability caching for performance and geographic distribution for latency The interviewer has…
If you’re preparing for multiple system design rounds and want guided practice across different scaling scenarios, our Guided and Bootcamp tiers include personalized feedback on your scaling strategies from experienced system architects.
Caching and Performance Optimization
We’ve mentioned caching multiple times. Now let’s go deeper on implementation decisions and performance characteristics.
Cache Placement: Where Does Redis Sit?
The cache sits between API servers and the database. Every redirect request follows this path:
1. API server receives GET /{short_code}
2. Check cache:
redis.get(short_code)
3. If found → return redirect immediately
4. If not found → query database → populate cache → return redirect
This is called a read-through cache or cache-aside pattern . The application is responsible for checking cache and populating it on misses.
Why not write-through? In write-through caching every database write also writes to cache For our use case this wastes effort newly created URLs rarely get immediate redirect traffic…
Cache Eviction: What Happens When Cache Fills Up?
Redis has finite memory. What happens when you’ve cached millions of URLs and run out of space?
LRU (Least Recently Used) eviction is standard When cache is full Redis evicts the URL that hasn’t been accessed in the longest time This naturally keeps hot URLs…
You can configure this in Redis:
maxmemory-policy allkeys-lru
“We’ll use LRU eviction so the cache automatically retains the most frequently accessed URLs. This gives us the highest possible cache hit rate without manual tuning.”
Cache Size: How Much Memory Do We Need?
Let’s do some back-of-envelope calculations—interviewers love this.
Assumptions:
– 1 billion total URLs in system
– Average short_code: 7 bytes
– Average original_url: 200 bytes
– Cache stores both: ~207 bytes per entry
We want to cache 10 million…
Calculation:
10M URLs × 207 bytes = 2.07 GB
Add overhead for Redis data structures: ~3 GB total.
We can cache the top 1 of URLs about 10 million entries in roughly 3 GB of Redis memory Given that URL access follows a power law distribution…
This type of napkin math shows you can reason about resource requirements, not just name technologies.
📥 Download: Cache Performance Worksheet
This one-page reference helps you quickly calculate cache memory requirements and estimate hit rates for different system design scenarios Includes formulas for working set size eviction rate estimation…
Download PDFCache Consistency: What If URLs Change?
In our basic design, URLs are immutable—once created, the mapping never changes. This makes caching trivial. No invalidation needed. Cache entries can live forever.
But if the interviewer asks about URL updates or deletions:
Update scenario: User changes where a short URL points.
When we update a URL mapping in the database we invalidate the cache entry redis delete short_code Next redirect request will cache-miss query the updated value from database…
Delete scenario: User deletes a short URL.
Same approach delete from cache when we delete from database We need to ensure these operations happen atomically or in the right order Delete cache first then database…
Cache stampede prevention: If a popular URL gets invalidated thousands of concurrent requests might all cache-miss simultaneously and hammer the database You can mention request coalescing or mutex…
Performance Targets: Measuring Success
By the end of this section, you should summarize the performance characteristics you’ve designed for:
Redirect latency (cache hit):
< 10ms
Redirect latency (cache miss):
< 100ms
Cache hit rate:
85-95%
URL creation latency:
< 200ms
Availability:
99.99% (< 1 hour downtime per year)
These numbers aren’t arbitrary. They come from the requirements you clarified at the start. You’re showing consistency across your design.
Rate Limiting, Abuse Prevention, and Reliability
System design interviews aren’t just about happy paths. Senior engineers need to think about what goes wrong and how to prevent or mitigate failures.
Rate Limiting: Preventing API Abuse
Without rate limiting , a malicious user could flood your system with URL creation requests, filling your database with garbage or running up costs.
Two rate limit scopes:
1. Per-IP rate limiting: Limit URL creations to, say, 10 per minute per IP address. This stops casual abuse from single sources.
Implementation: Use Redis with sliding window or token bucket algorithm. Store counters like
ratelimit:{ip}:{minute}
with TTL.
2. Per-user rate limiting: If you add authentication, limit each user account to, say, 1000 URL creations per day. This prevents account compromise from causing runaway resource usage.
I’d implement rate limiting at the API gateway or load balancer level using a token bucket algorithm Each IP gets 10 tokens per minute Creating a URL consumes…
This shows you understand both the concept (rate limiting) and practical implementation details (token bucket, HTTP status codes).
Abuse Prevention: Malicious Content
URL shorteners are notorious for hiding malicious links—phishing sites, malware, illegal content. How do you prevent this?
URL validation: Check submitted URLs against blacklists of known malicious domains. Services like Google Safe Browsing API provide this.
Content scanning: Before accepting a URL, fetch the destination and scan for malicious patterns. This adds latency but improves safety.
User reporting: Allow users to report malicious short URLs. Build a moderation queue for human review.
Expiration by default: Make URLs expire after 30 days unless explicitly renewed. This limits the lifespan of malicious links.
You don’t need to design a full abuse prevention system in the interview. Just show you’re aware of the problem: We’d integrate with URL reputation services to block…
Reliability: Handling Failures Gracefully
What happens when components fail? Strong candidates think about failure modes.
Database failure: If primary database fails promote a read replica to primary Writes may be unavailable for 30-60 seconds during failover Redirects continue working via cache and remaining…
Cache failure: If Redis crashes all traffic hits the database directly Performance degrades but system stays available Database might struggle under 100K requests sec so you’d need to…
API server failure: Load balancer detects unhealthy servers via health checks and routes traffic to healthy ones. Zero user impact if you have multiple servers.
For critical components like the database we run health checks and automated failover For stateless components like API servers we overprovision running 20 more capacity than needed so…
📊 Table: Failure Modes and Mitigation Strategies
Every distributed system has failure scenarios. Planning for them proactively differentiates senior engineers from junior ones. This table maps common failure modes to practical mitigation strategies.
| Component | Failure Mode | Impact | Mitigation Strategy |
|---|---|---|---|
| Primary Database | Crashes or becomes unavailable | Writes blocked, reads continue via replicas | Automatic failover to replica (30-60s downtime) |
| Read Replica | One replica fails | Reduced read capacity | Load balancer routes to healthy replicas |
| Cache (Redis) | Crashes or evicts all data | Database experiences full load (100K req/s) | Circuit breakers + graceful degradation + cache warm-up |
| API Server | Server crashes or becomes unresponsive | Reduced request handling capacity | Load balancer health checks remove from pool |
| Load Balancer | Single point of failure | Complete service outage | Active-passive LB pair with failover IP |
| Network Partition | Database shard unreachable | URLs on that shard unavailable | Multi-DC replication + consensus protocol |
Monitoring and Observability
You can’t fix what you can’t see. Production systems need monitoring.
Key metrics to track:
Golden signals:
Latency (p50, p95, p99), traffic (requests/sec), errors (error rate %), saturation (CPU, memory, disk)
Business metrics:
URLs created per minute, redirect success rate, cache hit rate
We’d use a monitoring stack like Prometheus Grafana or Datadog to track these metrics Set alerts on anomalies like cache hit rate dropping below 80 or p99 latency…
You don’t need to design the entire monitoring system. Just show awareness that production systems require observability.
Trade-Offs and Design Justification
This is where many candidates lose points. They make design decisions but never explain why they chose option A over option B Senior engineers don’t just build systems… trade-off analysis
Let’s walk through the major decision points in our URL shortener design and articulate the trade-offs explicitly.
Trade-Off 1: Short Code Generation Strategy
How do you generate the unique short codes? This is one of the first questions interviewers dig into.
Option A: Random ID Generation
Generate a random 6-7 character string (alphanumeric). Check database for collisions. If collision exists, generate another.
Pros:
Simple to implement. No coordination needed across servers. Each API server generates independently.
Cons:
Collision probability increases as database fills At 1 billion URLs with 7-character codes…
Option B: Auto-Incrementing Counter
Use a centralized counter. Each new URL gets the next number. Convert to base62 for short representation.
Pros:
No collisions ever. Predictable, sequential IDs.
Cons:
Centralized counter is a bottleneck and single point of failure Requires coordination Sequential IDs leak information competitors can estimate your…
Option C: Pre-Generated ID Pool
Generate millions of IDs in advance. Store them in a distributed pool. Each API server claims a batch from the pool when needed.
Pros:
No real-time generation overhead. No collisions. Scales well.
Cons:
Complex to implement. Need a reliable ID generation service. Wasted IDs if servers crash before using their batch.
Your interview answer:
I’d start with random generation it’s simple and works well until we hit hundreds of millions of URLs If collision rates become problematic we can move to a…
This shows you understand multiple approaches and can choose pragmatically based on scale.
📊 Table: Short Code Generation Trade-Offs
The short code generation strategy impacts performance, scalability, and security. Each approach has distinct strengths that become relevant at different scales.
| Approach | Implementation Complexity | Collision Handling | Scalability | Security |
|---|---|---|---|---|
| Random Generation | Low (simple, stateless) | Retry on collision (~1% at scale) | High (no coordination) | Good (unpredictable IDs) |
| Auto-Increment Counter | Medium (needs central coordination) | None (guaranteed unique) | Low (single bottleneck) | Poor (sequential, enumerable) |
| Pre-Generated Pool | High (requires ID service) | None (pre-validated) | Very High (distributed pools) | Good (can use random pool) |
| Hash-Based (MD5/SHA) | Low (deterministic hashing) | Possible (birthday paradox) | High (stateless) | Medium (predictable for same URL) |
Trade-Off 2: SQL vs NoSQL Database Choice
We touched on this earlier. Let’s make the trade-off explicit.
Choosing SQL (PostgreSQL):
We’re optimizing for strong consistency and simplicity SQL databases provide ACID guarantees we’ll never lose data or create duplicate short codes The access pattern primary key lookups performs…
Trade-offs accepted: Manual sharding complexity at massive scale. Schema migrations require planning.
Choosing NoSQL (DynamoDB):
We’re optimizing for horizontal scalability and operational simplicity DynamoDB auto-scales handles partitioning transparently and excels at single-key lookups We accept eventual consistency for replicas which is fine since…
Trade-offs accepted: Limited secondary query patterns. Higher cost at small scale. Vendor lock-in.
In the interview, you’re showing decision-making maturity: Both are viable I’d lean toward SQL for strong consistency guarantees and team familiarity knowing we can migrate to NoSQL later…
Trade-Off 3: HTTP 301 vs 302 Redirects
We discussed this in API design, but it’s worth restating as a conscious trade-off.
HTTP 301 (Permanent Redirect):
Benefit:
Browsers cache the redirect. Subsequent visits don’t hit your servers. Extremely fast for users. Reduces infrastructure costs.
Cost:
You lose visibility into clicks Can’t track analytics or…
HTTP 302 (Temporary Redirect):
Benefit:
Every click goes through your servers. Full analytics visibility. Can update destinations dynamically.
Cost:
Slightly slower for users. Higher server load. More infrastructure cost.
Your justification:
For a minimal URL shortener without analytics 301 is better optimize for speed and cost If we add click tracking as a feature we’d switch to 302 to…
Trade-Off 4: Cache Consistency vs Performance
If URLs can be updated or deleted, you face the classic cache consistency problem.
Strong consistency approach: Invalidate cache immediately when database updates. Ensures cache and database always match.
Benefit:
No stale data ever served.
Cost:
Cache invalidation adds latency to write operations. Risk of cache stampede if popular URL gets invalidated.
Eventual consistency approach: Set a short TTL on cache entries (e.g., 60 seconds). Updates propagate naturally when cache expires.
Benefit:
Simpler implementation. No invalidation logic needed.
Cost:
Users might see stale destinations for up to TTL duration after an update.
Your interview stance:
For our immutable URLs this isn’t an issue no invalidation needed If we add updates I’d use immediate invalidation for simplicity accepting the small write latency cost URLs…
Trade-Off 5: Simplicity vs Extensibility
Throughout this design, we’ve prioritized simplicity: basic features, straightforward architecture, minimal components. But what if requirements expand?
Current design trade-off:
We’ve built a simple system optimized for the core use case create short URLs redirect quickly scale reads This makes the system easy to build deploy and maintain…
Alternative approach: Build a more complex system upfront with microservices, event streaming, separate analytics pipeline.
Benefit:
Easier to add features later. Each service evolves independently.
Cost:
Massive upfront complexity. Harder to debug. Slower initial development.
Senior engineer perspective:
I’m choosing simplicity because we can always add complexity later when requirements demand it Overengineering early creates maintenance burden without proven benefit Start simple measure usage evolve based…
This philosophy—pragmatic incrementalism—is what separates candidates who’ve shipped production systems from those who’ve only read textbooks.
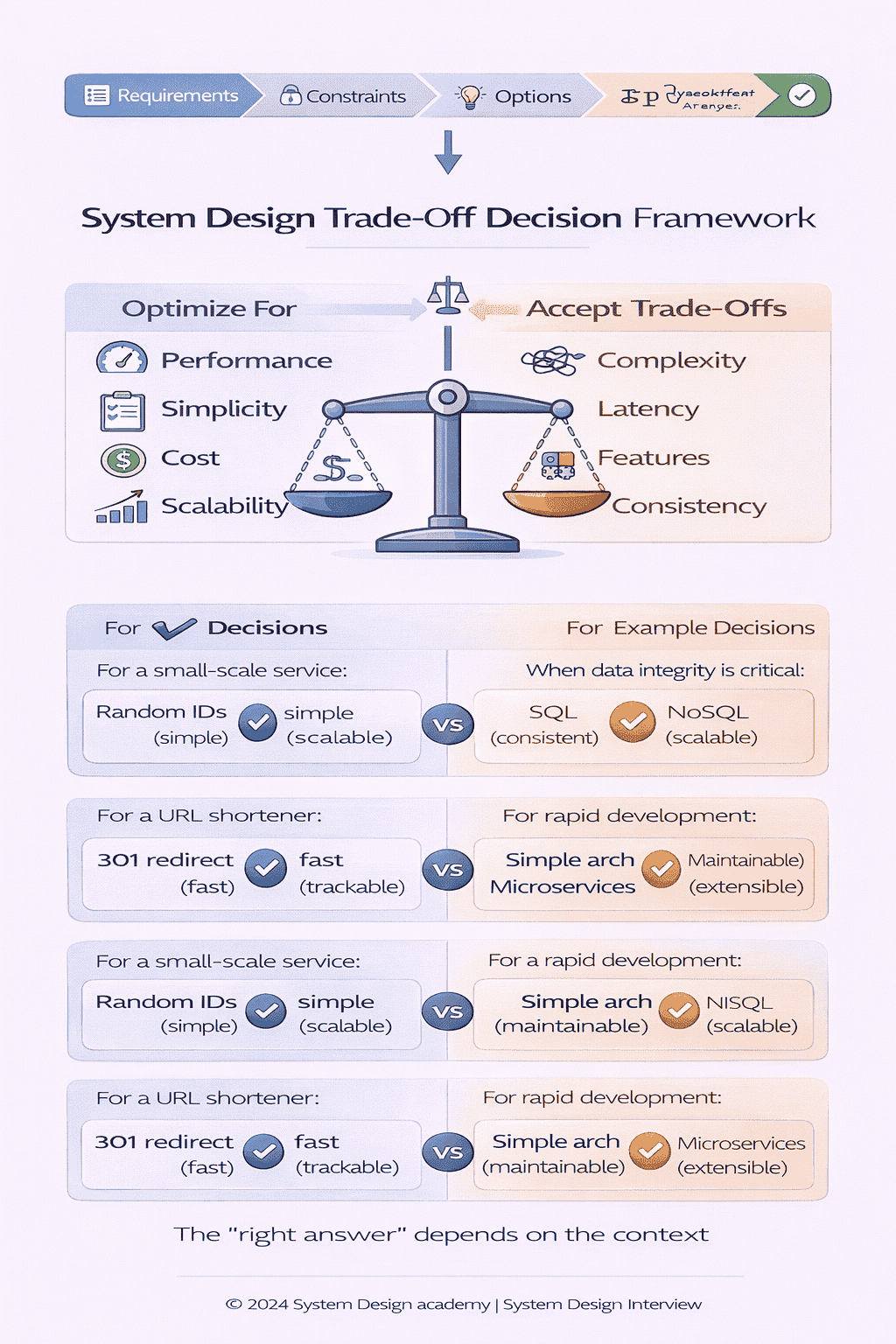
If you struggle with articulating trade-offs clearly in interviews, you’re not alone. This is the #1 area where experienced engineers need coaching. Our live mock interview sessions specifically focus on improving how…
Closing the Interview Strong
You’ve walked through requirements, API design, architecture, scaling, caching, and trade-offs. The interview is nearing its end. How do you close effectively?
Step 1: Summarize Your Design
Take 60-90 seconds to recap the complete system at a high level. This demonstrates you can see the forest, not just the trees.
Let me summarize the design we’ve built We have a URL shortener that accepts long URLs via a POST API generates unique short codes using random generation with…
This recap hits every major component without excessive detail. It shows you maintained big-picture awareness throughout the discussion.
Step 2: Acknowledge Limitations and Extensions
No design is perfect or complete in 45 minutes. Strong candidates explicitly acknowledge what they didn’t cover or what could be improved.
There are several areas we could extend with more time We haven’t discussed detailed disaster recovery procedures backup strategies point-in-time recovery multi-region failover We also simplified analytics away…
This shows intellectual honesty. You’re not claiming perfection—you’re showing you know what else exists beyond what was discussed.
Step 3: Demonstrate Adaptability
If the interviewer throws a late-stage curveball, show how your design adapts rather than starting over.
Interviewer: “What if we need to support 10 billion URLs instead of 1 billion?”
Strong response: At 10 billion URLs we’d definitely need to shard the database probably 32 or 64 shards using consistent hashing Our cache strategy remains the same but…
Interviewer: “What if we want to track detailed analytics on every click?”
Strong response: We’d switch from HTTP 301 to 302 redirects to ensure every click hits our servers Then we’d add an event streaming layer Kafka or Kinesis where…
These responses show you can evolve the design based on changing requirements without throwing everything away and starting over.
Step 4: Express Genuine Interest
If time remains, ask a thoughtful question about their actual system or tech stack. This shows you’re thinking beyond the interview exercise.
“I’m curious—for your production URL shortener or similar high-traffic service, what’s been the biggest scaling challenge you didn’t anticipate upfront?”
Or: “What database technology do you actually use for this type of workload in your infrastructure?”
These questions signal you’re genuinely interested in learning from their experience, not just performing for a score.
The Final Note
In live interview sessions, candidates often ask: “How do I know if I did well?”
Good signals:
- Interviewer engaged actively, asked follow-up questions
- You spent roughly equal time on API/architecture/scaling (not 80% on one area)
- You explained trade-offs explicitly multiple times
- You adapted the design based on interviewer constraints
- You maintained a conversational tone, not a monologue
Weak signals:
- Interviewer stayed silent, just taking notes
- You talked for 20 minutes without pausing for questions
- You couldn’t explain why you made specific choices
- You got stuck on one component and never finished the design
- You repeatedly said “it depends” without choosing an approach
Ultimately, system design interviews are about demonstrating senior-level thinking: structured problem-solving, clear communication, trade-off reasoning, and practical engineering judgment.
This guide has shown you the framework. Applying it consistently across different problems—URL shorteners, rate limiters, news feeds, chat systems—requires practice.
That’s where deliberate preparation comes in. If you want structured practice with 40+ system design problems using this exact interview framework, explore our complete curriculum And if you need personalized… Guided and Bootcamp coaching programs
Your Path to System Design Interview Mastery
You’ve just walked through a complete URL shortener system design interview from requirement clarification to closing statements This wasn’t a theoretical exercise It’s the exact framework that successful…
The URL shortener problem reveals something important: system design interviews don’t test what you know—they test how you think.
You now understand the structure. You’ve seen how to clarify requirements, design APIs before architecture, build systems incrementally, reason about scale, articulate trade-offs, and adapt to interviewer feedback.
But reading one walkthrough isn’t enough to internalize these patterns. Senior-level system design thinking develops through repeated, deliberate practice across different problem types.
What Separates Those Who Pass From Those Who Fail
After 150+ mock interviews with senior engineers, I’ve identified three critical success factors:
1. Structured thinking under pressure. You need a mental framework you can apply to any system design problem URL shorteners rate limiters notification systems search engines The framework…
2. Communication clarity. Your design could be technically perfect but if you can’t explain it clearly or respond to interviewer questions smoothly you’ll struggle This is a communication…
3. Trade-off articulation. Interviewers don’t expect perfect answers. They expect you to explain why you chose option A over option B what you’re optimizing for and what costs…
These skills develop through practice—preferably with feedback from someone who’s conducted these interviews professionally.
Next Steps: From Understanding to Mastery
If you’re preparing for upcoming system design interviews, here’s your action plan :
Step 1: Practice this framework on different problems. Take the URL shortener approach and apply it to designing a cache system a messaging queue or a web crawler…
Step 2: Time yourself. Real interviews give you 45 minutes. Practice completing full designs in that timeframe. You’ll learn to prioritize what matters and skip unnecessary details.
Step 3: Get feedback. Record yourself solving problems Watch the playback Are you explaining clearly Pausing for questions Spending too long on one area Self-review reveals patterns you…
Step 4: Study real system architectures. Read engineering blogs from companies like Netflix Uber Airbnb See how production systems handle scale failures and trade-offs This gives you concrete…
📥 Download: System Design Interview Preparation Checklist
This single-page checklist covers everything you need to prepare effectively for system design rounds core concepts to review practice problem categories framework steps to memorize and common pitfalls…
Download PDFWhy Self-Study Isn’t Always Enough
Many senior engineers have the technical knowledge to design excellent systems. But they struggle in interviews because they’ve never practiced verbalizing their thought process under time pressure.
You might think through trade-offs perfectly in your head but when you try to explain them out loud to an interviewer you stumble You jump between topics You…
This is where structured coaching makes a dramatic difference Having someone observe your interview performance identify communication gaps and give you specific feedback on pacing clarity and trade-off articulation accelerates…
Our System Design Interview Coaching Program is built specifically for this It’s not another course with pre-recorded videos It’s live practice with real-time feedback from architects who’ve conducted hundreds of system design interviews…
What You Get With Structured Preparation
Our program includes three tiers designed for different learning styles:
Self-Paced ($197): Complete curriculum covering 40+ system design problems with worked solutions, video walkthroughs, and downloadable resources. Perfect if you’re disciplined and have 2-3 months to prepare.
Guided ($397) : Everything in Self-Paced plus 3 live 1-on-1 coaching sessions where we review your designs provide personalized feedback and help you refine your communication approach Best for engineers who…
Bootcamp ($697): Maximum support 8 live coaching sessions 3 full mock interviews with detailed scoring personalized study plan and resume interview prep review For engineers who are serious…
All tiers include lifetime access, a 30-day money-back guarantee, and a 94% interview success rate among graduates.
See detailed comparison and enroll at geekmerit.com/pricing .
Final Thoughts
System design interviews feel intimidating because they’re open-ended and ambiguous There’s no right answer to memorize But that’s also what makes them fair they test your actual engineering…
The framework you’ve learned in this guide works. It’s proven across thousands of real interviews. Now it’s about internalizing it through practice until it becomes second nature.
You have the roadmap. The question is whether you’ll put in the deliberate practice needed to execute it under pressure.
If you’re committed to preparing seriously we’re here to help Our coaching program has helped 2 400 senior engineers land roles at Google Amazon Microsoft Meta and other…
Your next system design interview doesn’t have to feel like a black box With the right framework and structured practice you can walk in confident communicate clearly and…
Start your preparation today: geekmerit.com
Frequently Asked Questions
How long should I spend on requirement clarification in a URL shortener interview?
Spend 3-5 minutes on requirement clarification about 10 of your total interview time This seems brief but it’s enough to establish functional scope core features vs extensions non-functional…
Should I use SQL or NoSQL for a URL shortener system?
Both work well SQL databases like PostgreSQL provide strong consistency guarantees and work excellently for the primary-key lookup pattern NoSQL databases like DynamoDB offer easier horizontal scaling and…
What’s the best way to generate unique short codes?
For interviews random generation with collision checking is the simplest approach and works well up to hundreds of millions of URLs Generate a 6-7 character alphanumeric string check…
How do I handle the interviewer changing requirements mid-interview?
This is intentional interviewers want to see how you adapt When requirements change like adding analytics or increasing scale 10x don’t restart your design from scratch Instead explain…
What if I don’t know the answer to a specific technical question during the interview?
Be honest and work through it logically If the interviewer asks How does consistent hashing work and you don’t know the exact algorithm say I know it’s a…
How much detail should I go into on caching strategies?
Provide enough detail to show you understand caching practically not theoretically Mention where the cache sits between API servers and database what it stores short_code original_url mappings why…
Citations
- https://redis.io/docs/manual/eviction/
- https://aws.amazon.com/dynamodb/features/
- https://www.postgresql.org/docs/current/ddl-partitioning.html
- https://en.wikipedia.org/wiki/Consistent_hashing
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/301
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/302
- https://martinfowler.com/articles/patterns-of-distributed-systems/
- https://prometheus.io/docs/concepts/metric_types/
Content Integrity Note
This guide was written with AI assistance and then edited, fact-checked, and aligned to expert-approved teaching standards by Ram Arun . Ram has over 10 years of experience coaching software developers through technical interviews at top-tier companies including FAANG and leading enterprise organizations. His background includes conducting 500+ mock system design interviews and helping engineers successfully transition into senior, staff, and principal roles. Technical content regarding distributed systems, architecture patterns, and interview evaluation criteria is sourced from industry-standard references including engineering blogs from Netflix, Uber, and Slack, cloud provider architecture documentation from AWS, Google Cloud, and Microsoft Azure, and authoritative texts on distributed systems design.

