Design Notification System: The Complete System Design Guide for Interviews
When senior engineers encounter a design notification system system design interview question most immediately jump to drawing boxes and arrows They describe queues workers and APIs but they…
The notification system question evaluates your ability to clarify ambiguous requirements reason about distributed system trade-offs and communicate structured thinking under pressure Real-world experience building notification pipelines doesn’t…
This guide walks you through designing a notification system exactly the way interviewers expect demonstrating not just what to design but how to think out loud ask the…
Last updated: Feb. 2026
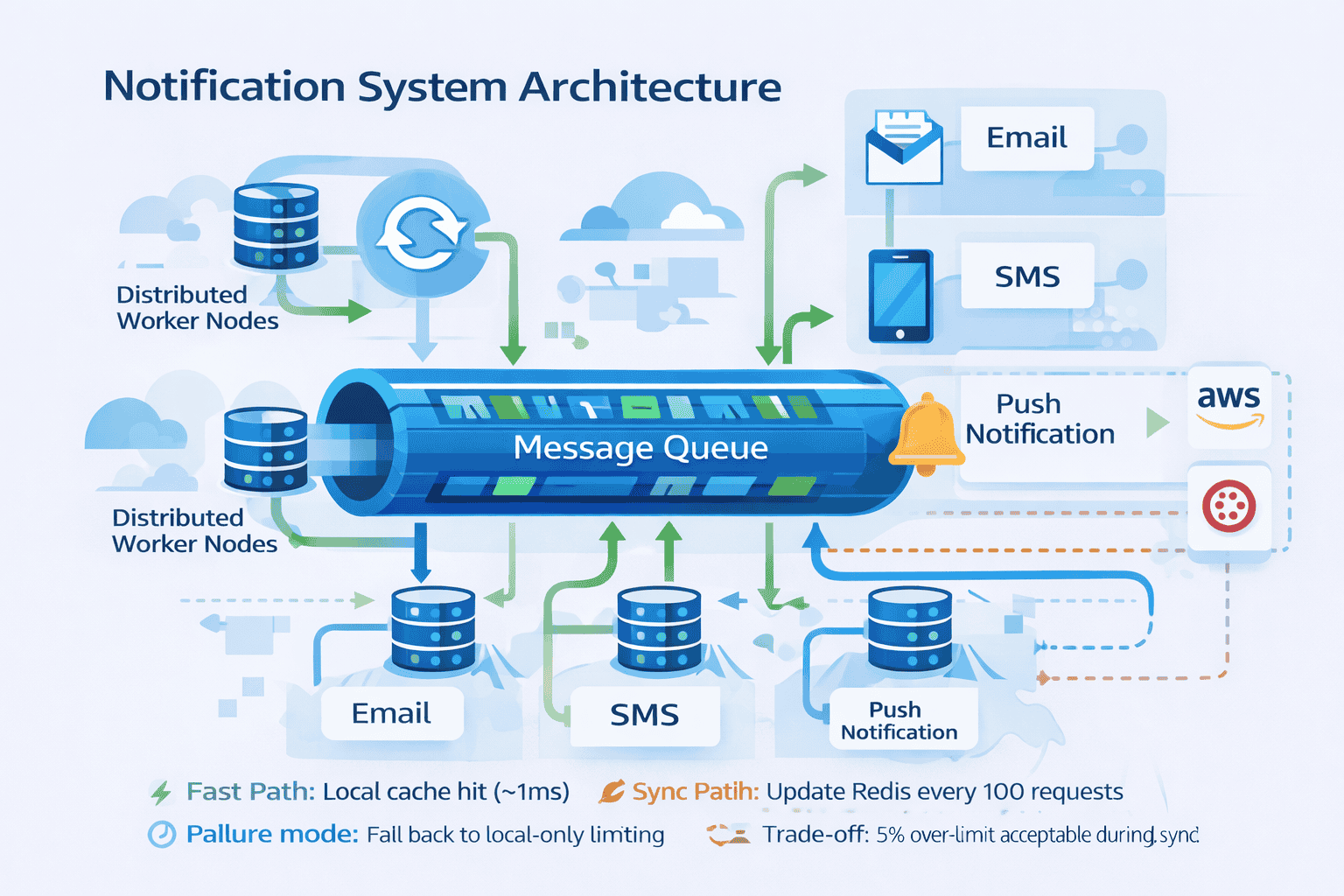
Table of Contents
- 1. What Interviewers Actually Test in Notification System Interviews
- 2. The Clarification Framework: Starting Like a Strong Candidate
- 3. Functional Requirements That Demonstrate Completeness
- 4. Non-Functional Requirements: Where Strong Candidates Stand Out
- 5. High-Level Architecture: The Interview Whiteboard Walkthrough
- 6. API Design: Practical, Minimal, Clear
- 7. Data Model: What to Persist and Why
- 8. Scaling Strategy: Handling Traffic Spikes and Flash Sales
- 9. From Theory to Interview Performance (Is coaching worth it?)
- 10. Frequently Asked Questions
Contents
What Interviewers Actually Test in Notification System Interviews
Notification system interviews rarely test your knowledge of specific technologies or frameworks Interviewers don’t care if you’ve used RabbitMQ versus Kafka or whether you’ve integrated with SendGrid versus…
The Real Evaluation Criteria
When interviewers ask you to design a notification system they’re testing four specific capabilities First your ability to clarify ambiguous requirements before committing to solutions Second your understanding…
Fourth and this is where most candidates fail whether you can adapt your design based on changing constraints Real interviews involve twists What if we need to send…
Why Production Experience Creates Blind Spots
Engineers with years of production notification system experience often perform worse in these interviews than those with less experience. The reason is counterintuitive but crucial to understand.
Production systems have established patterns vendor relationships and legacy constraints that guide decisions automatically You don’t question whether to use your company’s existing message bus you just use…
Interviews require you to make these decisions explicit justify them and explore alternatives The experienced engineer’s advantage pattern recognition and quick decision-making becomes a liability when interviewers expect…
The Communication Gap
System design interviews test your ability to think out loud and guide your interviewer through your reasoning process This feels unnatural In production work you internalize analysis research options privately and…
Strong candidates narrate their decision-making I’m choosing a message queue here because it decouples producers from consumers which gives us buffering during traffic spikes and allows independent scaling…
Weak candidates state decisions without justification We’ll use a message queue and immediately move to the next component The interviewer has no visibility into whether you understand the…
Before Drawing Any Boxes
The strongest signal you can send in the first 5 minutes of a notification system interview is slowing down to ask clarifying questions This pattern consistently separates senior…
Interviewers intentionally keep the initial prompt vague Design a notification system This ambiguity is a test Candidates who immediately start designing reveal they’re either making unstated assumptions or…
The next section provides a systematic framework for requirement clarification that demonstrates senior-level thinking from the opening moments of your interview.
The Clarification Framework: Starting Like a Strong Candidate
When an interviewer says Design a notification system your first instinct might be to acknowledge the prompt and start sketching components Resist this urge The opening 3-5 minutes…
Why Clarification Questions Matter More Than You Think
Clarification isn’t about demonstrating knowledge or impressing your interviewer with clever questions. It serves three critical functions that directly impact your interview performance and evaluation.
First it establishes scope boundaries Notification systems can range from simple email alerts to multi-channel platforms handling billions of messages daily Without clarification you might design for the…
Second it reveals your understanding of the problem domain When you ask about delivery guarantees channel priorities or user preference management you signal that you’ve thought deeply about…
Third it creates alignment with your interviewer Each answer they provide gives you information about what they care about If they emphasize scale your design should prioritize horizontal…
The Seven Essential Question Categories
Structure your clarification using these seven categories. You don’t need to ask every possible question—interviewers appreciate efficiency—but covering these areas demonstrates completeness in your thinking.
Notification types and use cases. Start here because it fundamentally shapes your architecture Ask What types of notifications will this system handle Are we supporting transactional notifications like…
This distinction matters enormously OTPs require low-latency delivery and high reliability Marketing emails can tolerate delays and lower delivery rates A system optimized for one often makes the…
Delivery channels. Continue with Which delivery channels do we need to support Email only or also SMS push notifications in-app messages and webhooks Each channel introduces different integration…
Email providers like SendGrid handle retries internally SMS providers often have strict rate limits and higher per-message costs Push notifications require device token management and platform-specific APIs Your…
Scale expectations. This question clarifies your optimization priorities What’s the expected scale Are we talking thousands of notifications per day millions per hour or something larger Follow up…
A system handling 10 000 notifications daily can use simpler architecture than one managing 10 million per hour The peak-to-average ratio determines whether you need elastic scaling or…
Latency requirements. Ask Are there latency requirements we need to meet Should security alerts deliver within seconds or can marketing campaigns process over hours Different notification types often…
This question helps you decide between synchronous and asynchronous patterns, choose appropriate queue depths, and design worker scaling policies.
📊 Table: Notification Types and Their Requirements
Different notification categories have fundamentally different requirements This table maps common notification types to their typical latency reliability and scale characteristics helping you understand trade-offs during the clarification…
| Notification Type | Latency Requirement | Reliability Need | Typical Scale | Cost Sensitivity |
|---|---|---|---|---|
| OTP / Security Alerts | < 30 seconds | Very High (must deliver) | Medium | Low (pay for speed) |
| Order Confirmations | < 2 minutes | High (expected) | Medium-High | Medium |
| Payment Receipts | < 5 minutes | High (compliance) | Medium | Medium |
| System Alerts | < 1 minute | Very High | Low | Low |
| Marketing Campaigns | Hours acceptable | Best Effort | Very High | High (cost optimize) |
| Product Recommendations | Not time-sensitive | Low (optional) | High | Very High |
| Shipping Updates | < 15 minutes | Medium-High | Medium | Medium |
User preferences and consent. Clarify Do users have preferences about which notifications they receive and through which channels How do we handle opt-outs and unsubscribes This question demonstrates…
User preferences introduce complexity You need a preferences service decision logic in your orchestration layer and audit trails for compliance But this complexity is necessary GDPR CAN-SPAM and…
Delivery guarantees. This is where you separate yourself from average candidates. Ask: “What delivery guarantees do we need? Is at-least-once delivery acceptable or do we need exactly-once Can we tolerate…
The answer fundamentally shapes your architecture At-least-once is dramatically simpler but requires idempotency in consumers Exactly-once is theoretically impossible in distributed systems but can be approximated with sufficient…
Integration patterns. Close with How will other services trigger notifications Are we supporting synchronous API calls event streams scheduled jobs or all of the above This reveals how…
If services expect synchronous confirmation that notifications were sent your API must respond quickly likely accepting requests and returning before actual delivery If they’re publishing events asynchronously your…
The Clarification Conversation in Practice
Strong candidates don’t mechanically list questions. They have a conversation that naturally covers these areas while reading the interviewer’s signals. Here’s how this might sound:
Before we dive into the design I’d like to clarify a few things about the notification system’s scope First what types of notifications are we supporting Are these…
Interviewer: “Focus on transactional notifications for now—payment confirmations, shipping updates, and account security alerts.”
“Got it. And which channels do we need? Email and SMS, or are push notifications and in-app messages also in scope?”
Interviewer: “Email, SMS, and push notifications. We can deprioritize in-app messages for this discussion.”
“Perfect. What’s the expected scale? Are we thinking millions of notifications daily, or is this more targeted?”
This conversational approach accomplishes several things simultaneously You’re gathering requirements demonstrating domain knowledge showing you can communicate complex topics clearly and building rapport with your interviewer These soft…
Once you’ve completed clarification explicitly summarize what you heard before moving to requirements This confirms alignment and gives your interviewer a chance to correct any misunderstandings So to…
Functional Requirements That Demonstrate Completeness
After clarification strong candidates explicitly state functional requirements before touching architecture This step signals systematic thinking and ensures you and your interviewer are aligned on what the system…
Why Functional Requirements Come Before Architecture
Jumping straight from clarification to architecture reveals immature engineering judgment Requirements define the problem Architecture defines the solution You can’t evaluate whether a solution is appropriate without first…
Explicit requirements also create a checklist you can reference throughout the design discussion When your interviewer asks How does your system handle scheduled notifications you can point back…
Core Functional Requirements for Notification Systems
Accept notification requests from multiple services. Your system must expose interfaces that allow various backend services to trigger notifications Payment services send receipt confirmations Authentication services dispatch OTPs…
This requirement implies you need a well-defined API contract support for multiple client authentication methods and the ability to handle varying request patterns from different source systems Some…
Support multiple delivery channels. Based on your clarification enumerate the channels email SMS push notifications Each channel requires integration with external providers distinct message formatting and channel-specific error…
State this explicitly The system must support email delivery via SMTP providers SMS delivery via telecom gateways and push notification delivery to iOS and Android devices through APNs…
Handle retries and failure scenarios. Distributed systems fail constantly External providers go down Network connections time out Rate limits get exceeded Your notification system must handle these failures…
This requirement drives significant architectural decisions where you persist messages how you track delivery attempts what retry policies you implement and how you eventually give up on undeliverable…
Respect user preferences and consent. Users control which notifications they receive and through which channels Someone might want order confirmations via email but not SMS Another user might…
Your system must check preferences before sending maintain an audit trail for compliance and handle preference updates that might be happening concurrently with notification requests This isn’t just…
Support delayed and scheduled notifications. Not all notifications send immediately Password reset links might delay by 30 seconds to prevent abuse Marketing campaigns schedule for specific times Reminder…
This requirement introduces time-based coordination challenges Your system needs a scheduling mechanism a way to cancel scheduled messages if conditions change and logic to handle timezone conversions when…
Provide delivery status tracking. Services that request notifications need to know outcomes Did the message deliver successfully Is it still pending Did it fail permanently This feedback enables…
Status tracking requires persistent storage of delivery attempts a query API for checking notification states and potentially webhooks or event streams to push status updates back to requesting…
How to Present Functional Requirements in Interviews
Don’t just list requirements. Frame them as a brief narrative that demonstrates you’ve thought about the user journey and system responsibilities. Here’s an effective presentation pattern:
Based on our clarification the notification system needs to accomplish six core functions First it must accept requests from multiple backend services authentication payments shipping each potentially using…
Third it needs robust failure handling including retries with exponential backoff and eventual dead-letter queueing for messages that can’t deliver Fourth it must check user preferences before every…
This framing takes 30 seconds but establishes that you understand the complete problem space It also gives your interviewer clear opportunities to interject if they want to adjust…
Common Mistakes in Stating Requirements
Weak candidates make three characteristic errors when presenting functional requirements First they list features without explaining why those features matter or what problems they solve The system should…
Second they confuse functional and non-functional requirements The system should be highly available describes a quality attribute not a function Functional requirements answer what does the system do…
Third they focus on implementation details rather than capabilities We’ll use Kafka for message queueing is a design decision not a requirement The functional requirement is accept and…
Non-Functional Requirements: Where Strong Candidates Stand Out
Non-functional requirements separate senior candidates from everyone else Anyone can list features Experienced engineers understand quality attributes and trade-offs This section determines whether you think like a senior…
Why Non-Functional Requirements Define System Architecture
Functional requirements tell you what components you need Non-functional requirements tell you how to build them A payment confirmation system with 99 9 availability looks completely different from…
Strong candidates explicitly state non-functional requirements and explain their implications This demonstrates you’re not just designing systems you’re making conscious trade-offs between competing concerns with full awareness of…
High Availability: Decoupling from Core Services
Requirement: The notification system must not block or slow down core business flows If the notification service is down users can still complete purchases create accounts and process…
Implication: This drives asynchronous architecture Services don’t wait for notification delivery before completing their primary operations A payment service commits the transaction publishes an event or makes an…
This pattern requires fire-and-forget semantics on the producer side and at-least-once delivery guarantees on the notification side You’ll need message persistence retry logic and operational tools to track…
Horizontal Scalability: Growing Without Redesign
Requirement: The system must scale horizontally to handle growth from thousands to millions of daily notifications without architectural changes. Adding capacity should mean adding servers, not rewriting code.
Implication: This rules out single-point architectures and requires stateless workers Your notification processors must be identical interchangeable units that pull work from shared queues Any worker can handle…
Horizontal scaling also influences your data partitioning strategy You’ll need to shard databases by user ID or notification ID avoid global locks and carefully design indexes to prevent…
📊 Table: Non-Functional Requirements and Architectural Impact
Each non-functional requirement drives specific architectural decisions. Understanding these connections helps you design systems that actually meet their quality attributes rather than just claiming to support them.
| Non-Functional Requirement | Target Metric | Key Architectural Decision | Trade-Off |
|---|---|---|---|
| High Availability | 99.9% uptime | Async processing, service isolation | Eventual consistency, added complexity |
| Horizontal Scalability | Linear capacity growth | Stateless workers, shared queues | Coordination overhead, no local state |
| Low Latency (Critical) | < 30s for OTPs | Priority queues, dedicated workers | Resource underutilization, higher cost |
| Idempotency | No duplicate sends | Deduplication cache , request IDs | Cache storage costs, TTL management |
| Observability | Real-time monitoring | Structured logging, metrics pipeline | Storage costs, query performance |
| Cost Efficiency | Minimize per-message cost | Batching, provider selection logic | Increased latency, added routing complexity |
Low Latency for Time-Sensitive Messages
Requirement: Security alerts and OTPs must deliver within 30 seconds. Payment confirmations should arrive within 2 minutes. Marketing emails can process over hours.
Implication: Not all notifications are equal. Your architecture needs priority queues or separate processing lanes for different latency classes. Critical notifications skip ahead of bulk marketing sends.
This might mean dedicated worker pools for high-priority messages separate queues with different consumer group assignments or priority-aware queue consumers that check critical queues first The specific implementation…
Idempotency: Preventing Duplicate Deliveries
Requirement: Retrying failed deliveries must not result in users receiving the same notification multiple times. Each unique notification request delivers at most once to each user.
Implication: You need deduplication logic Every notification request includes an idempotency key typically a hash of user ID notification type and relevant identifiers like order ID Before sending…
This requires persistent storage for processed idempotency keys TTL policies to expire old entries and careful handling of race conditions when multiple workers might process duplicate requests simultaneously…
The interviewer might probe deeper How do you handle idempotency keys from different services that might conflict Strong answer use namespaced keys that include the requesting service ID…
Observability and Auditability
Requirement: Operations teams must monitor delivery rates, latency distributions, and failure patterns in real-time. Compliance teams must audit who received what notification and when, with immutable logs.
Implication: Build observability into the system from day one, not as an afterthought. Every notification produces structured logs capturing request details, processing steps, provider responses, and final outcomes.
These logs feed into metrics aggregation systems for real-time dashboards and long-term storage for compliance queries You’ll need log retention policies search capabilities and potentially separate hot and…
Cost Efficiency: Provider Selection and Batching
Requirement: Minimize per-message costs while meeting delivery SLAs. Different providers offer different pricing models—some charge per message, others per batch, some have volume discounts.
Implication: Your system needs provider selection logic For marketing emails route to the cheapest provider that meets latency requirements For critical OTPs use the most reliable provider regardless…
You might also batch messages where latency allows Sending 1 000 emails individually costs more than batching them into a single API call to your email provider But…
Stating This Explicitly in Interviews
After presenting functional requirements, transition to non-functional with explicit framing: “Now let me outline the key quality attributes this system needs to support.”
First high availability The notification system must not block core business flows If it’s down users can still complete purchases This means asynchronous processing throughout services fire-and-forget notification…
Second horizontal scalability We should be able to grow from thousands to millions of daily notifications by adding workers not by rewriting code This requires stateless processors and…
“Third, differentiated latency. OTPs need 30-second delivery, but marketing emails can process over hours. We’ll need priority queues or separate processing lanes.”
“Fourth, idempotency. Retries must not create duplicate deliveries. We’ll use deduplication based on idempotency keys.”
“Finally, observability. Real-time metrics for operations, immutable audit logs for compliance.”
This presentation takes 60 seconds but demonstrates senior-level thinking about system qualities. You’ve shown awareness of availability patterns, scaling models, latency management, exactly-once semantics challenges, and operational requirements.
Many interviewers will interrupt during this section to explore trade-offs. That’s perfect—it means you’ve surfaced the interesting technical decisions that make for good interview discussions.
High-Level Architecture: The Interview Whiteboard Walkthrough
With requirements established you can finally design the system This is where most candidates start and why they struggle Without explicit requirements their architectures lack justification With requirements…
The Layered Architecture Pattern
Strong notification system designs follow a layered architecture that cleanly separates concerns Each layer has a single responsibility making the system easier to reason about scale and maintain…
I’m going to structure this as a layered system with six main components each handling a distinct part of the notification lifecycle Working from top to bottom ingestion…
Layer 1: Notification API and Ingestion
The entry point accepts notification requests from backend services This layer exposes RESTful APIs or accepts events from message streams validates incoming requests enforces rate limits to prevent…
Key architectural decision this layer does not actually send notifications It accepts requests validates them writes them to durable storage and returns success Actual delivery happens asynchronously This…
The interviewer might ask Why persist before acknowledging Why not write to the queue directly Strong answer durability guarantees If you acknowledge before persisting you might lose the…
Layer 2: Message Queue and Event Stream
The ingestion layer publishes accepted requests to a message queue or event stream This component decouples producers from consumers buffers traffic spikes and enables independent scaling of processing…
When discussing message brokers in interviews avoid immediately naming technologies First explain the requirements We need a distributed queue that supports partitioning for parallel processing message ordering within…
This answer demonstrates you understand trade-offs rather than defaulting to whatever technology you’re most familiar with.
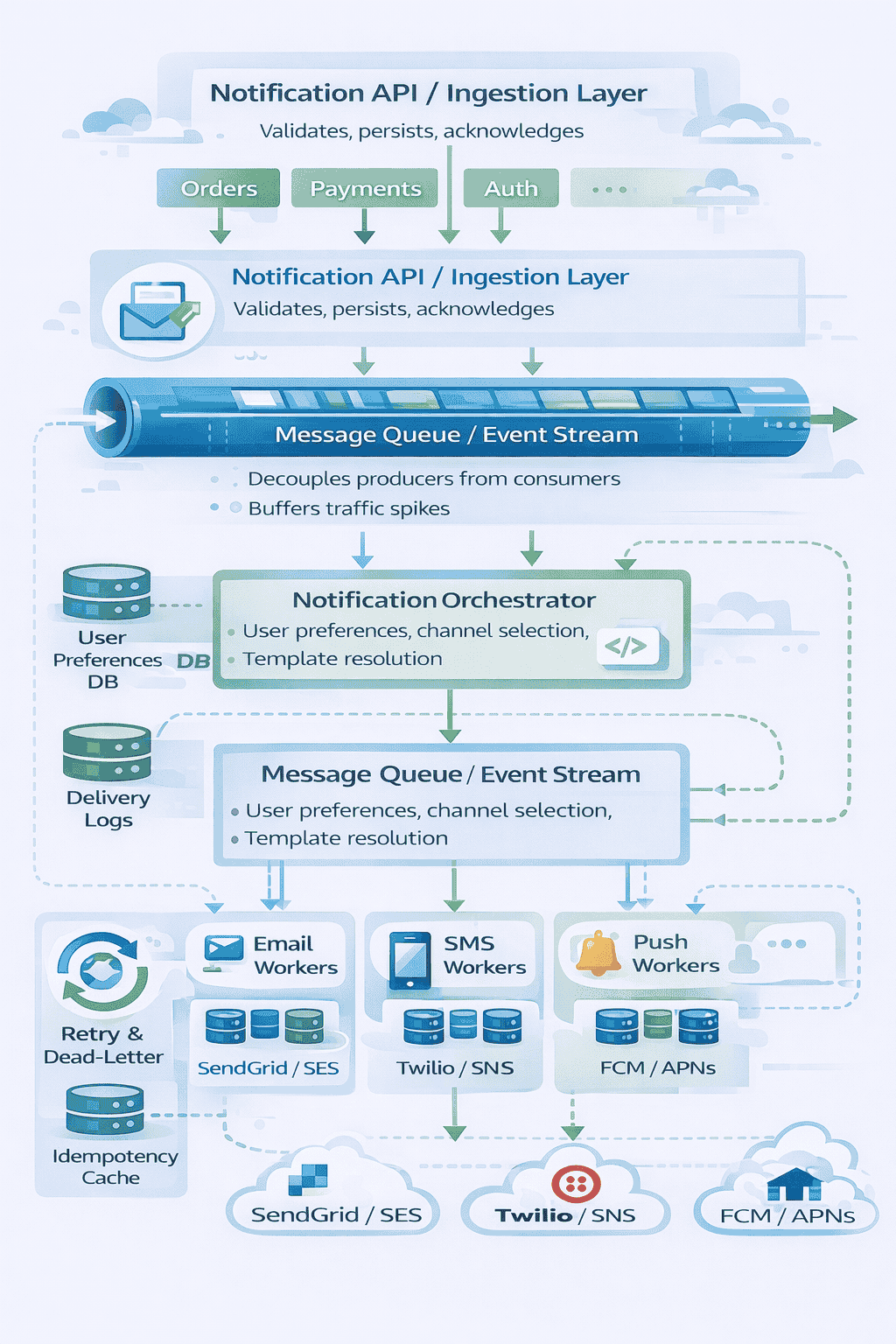
Layer 3: Notification Orchestrator
Workers consume messages from the queue and apply business logic before actual delivery The orchestrator checks user preferences is this user opted in for this notification type It…
This component is crucial but often overlooked in weak designs Candidates jump from queue to sending without explaining where preference checking happens how templates work or where channel…
State an important property The orchestrator is stateless Each notification is processed independently State lives in the preferences database and template storage not in worker memory This means…
Layer 4: Channel-Specific Workers
After orchestration determines that a notification should send via email SMS or push channel-specific workers handle the actual provider integration These workers understand provider APIs rate limits retry…
Separating channel workers from orchestration allows independent scaling and specialization Email workers might batch messages before calling SendGrid’s bulk API SMS workers implement backoff strategies for rate-limit errors…
Each worker type pulls from its own queue or queue partition The orchestrator publishes to email-queue sms-queue or push-queue based on selected channels This separation prevents a problem…
Layer 5: External Provider Integration
Channel workers call external services SendGrid for email Twilio for SMS Firebase Cloud Messaging for Android push Apple Push Notification Service for iOS These are third-party dependencies outside…
Strong candidates explicitly acknowledge this External providers are failure points They have rate limits scheduled maintenance windows and occasional outages Our architecture must assume these calls will sometimes…
This acknowledgment sets up the next component naturally.
Layer 6: Retry and Dead-Letter Handling
When provider calls fail retry logic determines what happens next Immediate retry on transient errors like network timeouts Exponential backoff for rate-limit errors Eventual dead-letter queueing for permanent…
Explain the retry strategy explicitly We’ll implement exponential backoff with jitter First retry after 1 second then 2 4 8 up to a maximum of 300 seconds After…
The dead-letter queue is where permanently undeliverable messages accumulate. Operations teams monitor this queue, investigate patterns, and potentially fix configuration issues or clean up invalid data.
Walking Through a Single Notification
After presenting the architecture, walk through an example notification end-to-end. This demonstrates you understand how components interact and gives your interviewer opportunities to probe failure scenarios.
Want another end-to-end practice problem after this one? Try: Design File Storage System – System Design Interview.
“Let me walk through what happens when a user completes a purchase and the payment service needs to send a receipt email.”
First the payment service calls our notification API with a POST request containing user ID notification type payment_receipt template ID and metadata including order ID and amount The…
An orchestrator worker consumes the message queries the user preferences service to confirm this user wants payment receipts via email selects the email channel resolves the receipt template…
An email worker picks up the message calls SendGrid’s API with the formatted email receives a 200 OK response logs the successful delivery with timestamps and updates the…
If SendGrid had returned a 429 rate-limit error the email worker would have requeued the message with backoff metadata incrementing the retry count After the backoff period another…
This narrative accomplishes several things It shows you’ve thought about the happy path and failure scenarios It demonstrates understanding of async patterns the payment service gets immediate confirmation…
API Design: Practical, Minimal, Clear
After establishing architecture interviewers often zoom into specific components API design is a common deep-dive because it reveals your understanding of contracts versioning error handling and client-server interaction…
The Core Notification Request Endpoint
Your notification system exposes a primary endpoint for accepting notification requests. Design this interface before discussing implementation details. Start by stating the HTTP method and path explicitly.
We’ll expose a POST endpoint at api v1 notifications for creating notification requests POST is appropriate because we’re creating resources and this operation has side effects The v1…
Request Payload Structure
The request body contains everything needed to process and deliver a notification. Design a minimal but complete schema that balances flexibility with type safety.
A typical request includes five key fields. User identifier specifies the recipient This might be a user ID from your authentication system an email address or a phone…
Notification type categorizes the notification for preference checking and analytics Examples include payment_receipt otp_verification shipping_update or marketing_campaign This field drives orchestration logic different types might have different default…
Template identifier references the message template to use Rather than having clients construct message content they reference pre-approved templates by ID This separation ensures consistent messaging supports internationalization…
Metadata object provides template variables For a payment receipt this includes order_id amount and transaction_date For an OTP it includes the code and expiration time Keep metadata structure…
Idempotency key enables safe retries Clients generate a unique key for each logical notification often a hash of user ID notification type and relevant business entity ID If the same…
📊 Table: API Request and Response Examples
Concrete examples make API design tangible. This table shows request payloads for different notification scenarios and the corresponding success responses your API should return.
| Scenario | Request Payload Example | Success Response |
|---|---|---|
| Payment Receipt |
{
|
202 Accepted
|
| OTP Verification |
{
|
202 Accepted
|
| Scheduled Marketing |
{
|
202 Accepted
|
Optional Fields for Advanced Use Cases
Beyond the core fields, support optional parameters for specific scenarios. Priority allows clients to mark time-sensitive notifications Values might be high normal or low mapping to different processing…
Scheduled delivery time supports delayed notifications Clients provide an ISO 8601 timestamp and your system holds the notification until that time This requires a scheduling component often implemented…
Channel preferences let clients override default channel selection A notification might default to email but the client can specify SMS only for this instance Use sparingly most channel…
Callback URL provides a webhook for delivery status updates When the notification delivers or permanently fails your system POSTs the outcome to this URL This creates an event-driven…
Response Design and Status Codes
Return 202 Accepted for successful request acceptance This status code signals that the request is valid and queued for processing but delivery hasn’t completed This matches your asynchronous…
The response body contains a notification ID and current status The ID allows clients to query delivery status later The status is typically queued or processing at this…
For errors use appropriate 4xx codes with descriptive messages 400 Bad Request for malformed JSON or missing required fields 401 Unauthorized for authentication failures 429 Too Many Requests…
Avoid 5xx errors when possible. A well-designed API handles predictable failures gracefully with 4xx codes. Reserve 500 Internal Server Error for truly unexpected conditions like database connectivity loss.
Idempotency Implementation Details
Interviewers often probe idempotency deeply because it’s conceptually simple but implementation is nuanced. Be prepared to discuss mechanics, not just the concept.
When a request arrives with an idempotency key check a distributed cache Redis is a common choice for that key If found return the cached response immediately without…
The TTL is important Idempotency keys shouldn’t live forever they consume cache memory and most retry scenarios happen within minutes or hours not days A 24-hour TTL handles…
Edge case what happens if two requests with the same idempotency key arrive simultaneously before either completes processing You need distributed locking or compare-and-set operations in your cache…
Query API for Delivery Status
Beyond creating notifications, clients need to check delivery status. Design a simple query endpoint: GET `/api/v1/notifications/{notification_id}`. This returns the current state and delivery history.
The response includes notification metadata, current status (queued, processing, sent, delivered, failed), timestamps for each state transition, delivery attempts with provider responses, and final outcome if processing completed.
For clients tracking many notifications, support batch queries: GET `/api/v1/notifications?ids=ntf_123,ntf_456,ntf_789`. This reduces round trips compared to individual queries.
Consider pagination for list endpoints If a client needs to query all notifications for user X in the last 24 hours support cursor-based pagination to handle large result…
Presenting API Design in Interviews
When interviewers ask about your API, don’t just describe the request schema. Frame it as a contract that enables specific behaviors and handles failure modes.
The notification API exposes a POST endpoint accepting user ID notification type template ID metadata and an idempotency key It returns 202 Accepted with a notification ID signaling…
Idempotency keys enable safe retries If the same key appears multiple times we process it once and return cached responses This handles network failures where clients retry uncertain…
“For status tracking, we expose a query API where clients poll notification state. For event-driven integrations, clients can provide webhook URLs that receive delivery updates.”
This presentation is concise, covers the key patterns, and naturally leads to follow-up questions about implementation details—exactly what makes for a good interview discussion.
Data Model: What to Persist and Why
Data modeling in system design interviews tests your understanding of what information needs persistence how to structure it for query patterns and when to accept denormalization for performance…
The Minimal Data Model Principle
In production systems you might normalize data extensively and track every possible field In interviews focus on the essential minimum that supports your stated requirements Every table and…
State this principle explicitly I’m going to focus on the core data we absolutely need to persist In production we’d likely track additional analytics and operational metadata but…
Entity 1: Notification Requests
The notification_requests table stores every incoming request This serves three purposes durability debugging and compliance If something goes wrong you can trace back to the original request If…
Key fields include notification_id primary key user_id indexed for user-based queries notification_type template_id metadata_json the template variables idempotency_key indexed for deduplication priority scheduled_delivery_time nullable created_at and request_source which…
The metadata field is JSON or JSONB in PostgreSQL because its structure varies by notification type You could normalize this into separate columns but that creates schema fragility…
Entity 2: Delivery Attempts
The delivery_attempts table tracks every attempt to send a notification One notification request might have multiple attempts if retries occur This table answers when did we try to…
Fields include attempt_id primary key notification_id foreign key to requests indexed attempt_number 1 2 3 channel email SMS push provider SendGrid Twilio FCM provider_request_id their tracking ID provider_response_code…
Why separate attempts from requests Query patterns Operations teams need to analyze what’s our success rate with SendGrid this hour They query delivery_attempts filtering by provider and time…
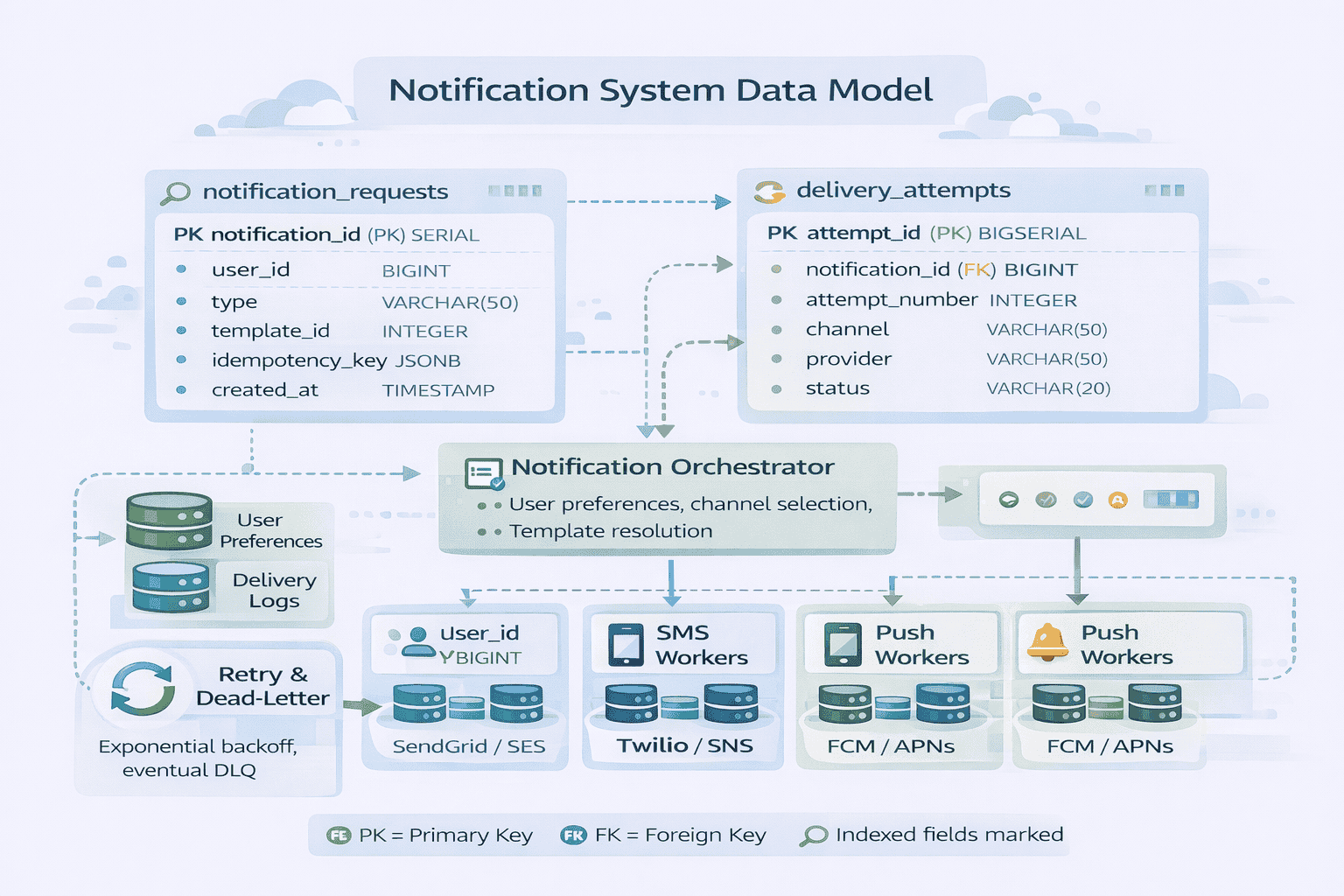
Entity 3: User Preferences
User preferences control which notifications a user receives and through which channels This table is read-heavy every notification checks preferences before sending Write operations are rare users update…
Structure this as user_id primary key or part of composite key notification_type to allow per-type preferences enabled_channels array or JSON email push global_opt_out boolean and updated_at for auditing…
One design decision to discuss should this be one row per user or one row per user-notification-type pair The tradeoff is storage versus query complexity One row per…
Entity 4: Aggregated Notification Status
When clients query notification status they don’t want to scan through delivery attempts counting retries They want the current state was it delivered This is a denormalized view…
Fields include notification_id (primary key, maps 1:1 with requests), current_status (queued, processing, sent, delivered, failed), delivered_at (nullable), failed_reason (nullable), final_channel_used, total_delivery_attempts, and last_updated.
This table is updated by workers after each delivery attempt It’s essentially a materialized view of the current notification state trading write overhead for fast read queries Clients…
Database Technology Choices
Interviewers often ask “What database would you use?” Strong answers discuss requirements before naming technologies. Weak answers jump to “I’d use PostgreSQL” without justification.
Frame your answer around access patterns For notification requests and delivery attempts we need transactional writes complex queries for debugging and JSON field support Relational databases like PostgreSQL…
For user preferences we need fast reads at high concurrency since we check preferences for every notification A caching layer in front of the database Redis or Memcached…
For real-time status updates we might consider a key-value store like Redis for the aggregated status table Notification status queries are simple gets by ID which key-value stores…
This answer demonstrates you understand different database strengths and make technology choices based on workload characteristics rather than familiarity or trends.
Partitioning and Scaling the Data Layer
As notification volume grows, single-database architectures hit limits. Discuss sharding strategies when interviewers probe scale.
We’d partition notification_requests and delivery_attempts by notification_id hash This distributes writes and reads evenly across shards Queries by notification_id which is our primary access pattern go to a…
“For user_preferences, we’d shard by user_id since all queries include user ID. This keeps all preferences for a given user on one shard, avoiding cross-shard joins.”
Time-based partitioning is another option worth mentioning For long-term retention of delivery attempts we could partition by month Recent months stay on fast storage for operational queries Older…
What Not to Persist
Strong candidates also know what not to model Template content doesn’t belong in this database it lives in a separate template service or configuration store Device tokens for…
State this explicitly I’m intentionally not modeling templates device tokens or full provider responses here Those live in separate services or are handled transiently This keeps our core…
This demonstrates architectural judgment—knowing where boundaries between components should be and when data belongs in different systems.
Scaling Strategy: Handling Traffic Spikes and Flash Sales
Interviewers frequently introduce scaling scenarios mid-interview to test your ability to adapt designs under changing constraints The classic prompt What happens during a flash sale when we need…
Why Scaling Questions Reveal Design Quality
Systems that scale gracefully share common characteristics stateless components horizontal partitioning asynchronous processing and deliberate bottleneck identification If your initial design lacks these properties scaling requires architectural changes…
When the scaling question comes respond with confidence The architecture I’ve described scales horizontally by design Let me walk through how it handles this specific scenario and where…
Scaling the Ingestion Layer
During traffic spikes your API receives far more requests per second than usual A flash sale triggers order confirmations A security incident generates authentication alerts for millions of…
The ingestion layer scales horizontally because it’s stateless Each API server independently accepts requests validates them writes to the database and publishes to the message queue Adding capacity…
The potential bottleneck isn’t the API servers it’s the database accepting writes Discuss this explicitly Under extreme load database write throughput becomes the constraint We have two strategies…
Second we can partition the notification_requests table by hash Multiple database shards accept writes in parallel The API server hashes the notification_id to determine which shard receives the…
Scaling the Message Queue
Message queues like Kafka or RabbitMQ scale horizontally through partitioning. When discussing your queue layer, explain partition strategy deliberately.
We’ll partition the notification queue by notification_id hash This distributes messages evenly across partitions Kafka handles partition assignment automatically as we add partitions it rebalances producers and consumers…
Address the common concern about ordering Within a partition Kafka guarantees message order Across partitions no global ordering exists For notifications this is acceptable we don’t need to…
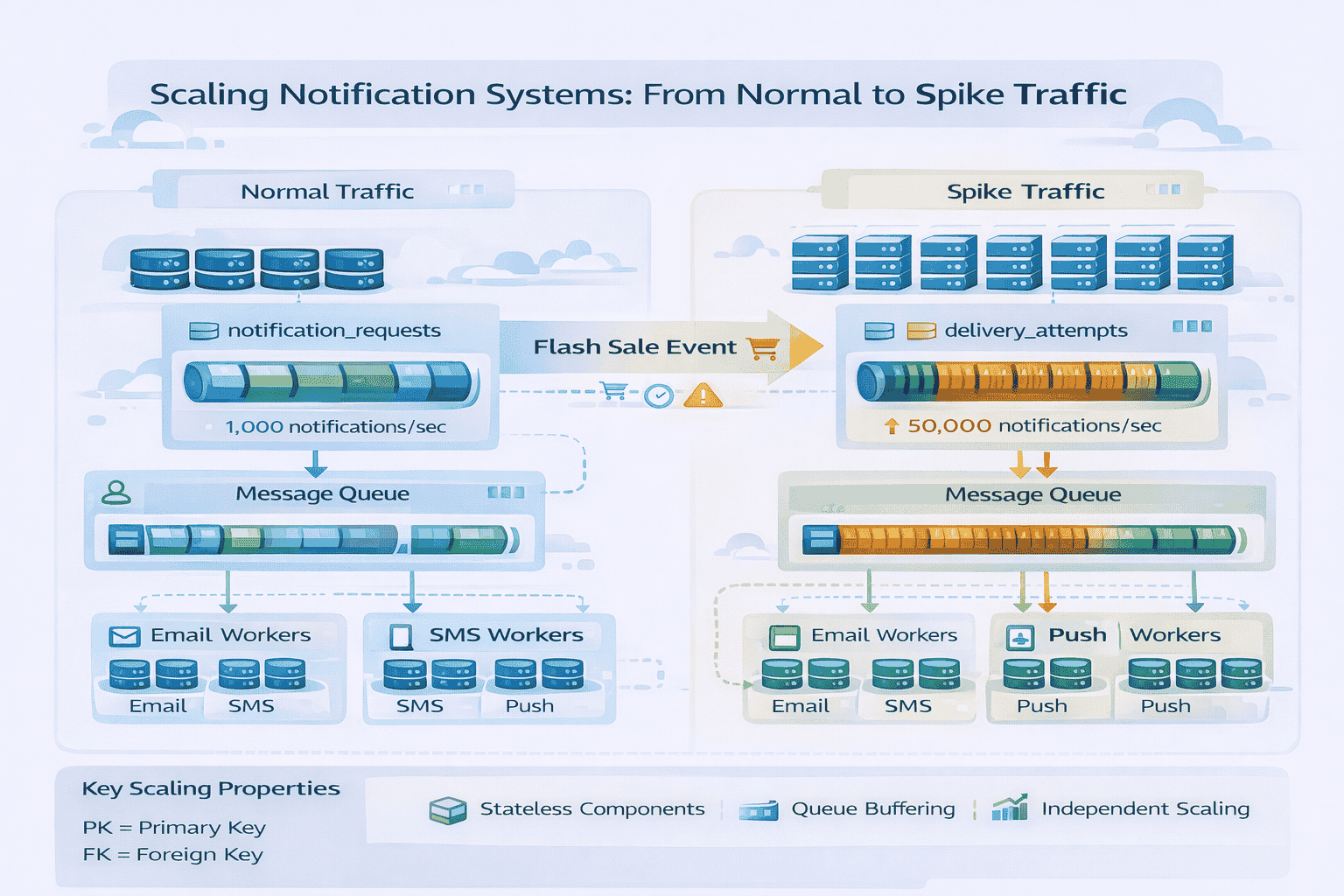
Scaling Worker Pools
Worker pools consume from queue partitions and process notifications. Scaling workers is straightforward: add more consumer processes. Kafka’s consumer group protocol automatically rebalances partitions across available workers.
Each worker type email SMS push has its own consumer group reading from its dedicated queue Adding workers to a group increases parallelism If we have 8 partitions…
Discuss autoscaling triggers explicitly We’d configure autoscaling based on queue depth and processing lag If the email queue has 100 000 unprocessed messages and lag exceeds 5 minutes…
This demonstrates you understand operational metrics and capacity planning, not just theoretical scalability.
Provider Rate Limits and Backpressure
External providers impose rate limits SendGrid might accept 1 000 emails per second Twilio limits SMS to 500 per second per account These limits create backpressure your workers can process…
Strong candidates address this proactively External providers are the ultimate bottleneck We can scale workers infinitely but SendGrid’s rate limit is fixed Our workers need rate limiting logic…
For planned spikes like marketing campaigns we’d batch notifications over time rather than sending everything immediately Schedule 10 million emails to send over 2 hours instead of 5…
This answer shows production awareness. Interview performance improves when you acknowledge real-world constraints instead of assuming infinite scalability.
Database Scaling Under Read and Write Pressure
As notification volume grows database operations become bottlenecks Writes to notification_requests and delivery_attempts increase linearly with traffic Reads for user preferences happen on every notification Status queries might…
For write scaling partition by notification_id as discussed in the data model section We’d use consistent hashing to map notification_ids to database shards Each shard is an independent…
For read scaling on user preferences aggressive caching is essential User preferences change rarely but are read on every notification We’d cache them in Redis with a 1-hour…
Status queries require different optimization For real-time status queries we’d maintain aggregated status in Redis as workers update it Clients query Redis instead of the database The database…
📊 Table: Component Scaling Characteristics
Different system components scale through different mechanisms. Understanding each component’s scaling properties helps you identify bottlenecks and design appropriate capacity strategies.
| Component | Scaling Method | Scaling Limit | Bottleneck | Mitigation Strategy |
|---|---|---|---|---|
| API Servers | Horizontal (stateless) | Database write capacity | Transaction throughput | Batch writes, partition database |
| Message Queue | Add partitions | Broker disk I/O | Message persistence speed | SSD storage, compression, retention policies |
| Orchestrator Workers | Horizontal (consumer groups) | Partition count | Cannot exceed partition count | Over-partition initially (32+ partitions) |
| Channel Workers | Horizontal (independent) | Provider rate limits | External API throughput | Rate limiting, multiple providers, batching |
| User Preferences DB | Read replicas + cache | Cache hit rate | Cache misses cause DB load | Longer TTLs, cache warming, read replicas |
| Notification DB (writes) | Partitioning/sharding | Coordinator overhead | Cross-shard queries | Design queries to hit single shards |
Cost Optimization During Scale
Scaling isn’t just about handling more load—it’s about doing so cost-effectively. Interviewers at companies conscious of cloud spending appreciate candidates who think about efficiency.
During normal load we run minimal baseline capacity As queue depth increases autoscaling adds workers But we’d configure scale-down delays don’t immediately terminate workers when load drops Traffic…
For planned campaigns we’d use reserved or spot instances for batch processing Marketing emails don’t need instant delivery We can process them over hours using cheaper compute capacity…
For provider costs we’d implement smart routing If SendGrid charges 0 001 per email and Mailgun charges 0 0008 route non-critical emails to Mailgun For critical OTPs where…
Monitoring and Observability During Spikes
Scaling systems need instrumentation to understand behavior under load. Discuss observability as part of your scaling strategy, not as an afterthought.
We’d instrument every component with metrics API request rate and latency queue depth per partition worker processing rate provider response times and error rates During traffic spikes these…
Distributed tracing tracks individual notifications through the entire system If delivery latency spikes during a flash sale traces show whether the bottleneck is in orchestration a specific channel…
Strong candidates connect monitoring to operational response When email queue depth exceeds thresholds but email workers are scaling slowly alerts fire Operations can manually add capacity or adjust…
Handling the Flash Sale Scenario: Complete Walkthrough
When the interviewer asks about 10 million notifications in 5 minutes, walk through the entire system response systematically.
First the flash sale triggers 10 million order confirmations hitting our API in a compressed timeframe The load balancer distributes requests across API servers As request rate increases…
Each API server batches writes to the database grouping 100 requests per transaction This reduces 10 million transactions to 100 000 which our partitioned database cluster handles Messages…
Orchestrator workers consume from Kafka checking user preferences and selecting channels We’d scale from 16 baseline orchestrators to 64 during the spike Orchestrated notifications publish to channel-specific queues…
Email workers scale from 20 to 100 consuming messages and calling SendGrid’s API But here’s where rate limits matter SendGrid accepts 1 000 emails per second At that…
The message queue buffers the excess Queue depth increases during the spike then drains over the next few hours From the user’s perspective their order confirmation might arrive…
This walkthrough demonstrates you understand every component’s role, identify the true bottleneck (provider rate limits), and design for graceful degradation rather than catastrophic failure.
What Happens When Scaling Isn’t Enough
Strong candidates acknowledge limits. Sometimes, horizontal scaling and optimization aren’t sufficient. Discuss these scenarios honestly.
If business requirements truly demand 10 million notifications in 5 minutes and we’re rate-limited by providers we need multiple provider accounts or enterprise agreements with higher limits Architectural…
Alternatively we’d challenge the requirement Do all 10 million notifications need to deliver in 5 minutes For order confirmations users care that they receive confirmation not that all…
This demonstrates maturity—recognizing when problems require business conversations, not just technical solutions. Interviewers appreciate candidates who understand engineering serves business goals, not the other way around.
Master System Design Interviews with Expert Guidance
You’ve just learned how to design notification systems the way interviewers expect But reading frameworks is different from applying them under interview pressure That’s where structured practice personalized…
geekmerit.com: Built for Senior .NET Developers
The only system design course created specifically for experienced NET developers preparing for interviews Skip the basics you already know Focus on architectural patterns trade-off analysis and interview communication frameworks that…
Three Learning Paths to Match Your Style
- ✓ Self-Paced ($197): All course content, 200+ practice problems, lifetime access
- ✓ Guided ($397): Everything in Self-Paced + 3 live coaching sessions + personalized feedback
- ✓ Bootcamp ($697): Maximum support with 8 coaching sessions + 3 full mock interviews
30-day money-back guarantee • Lifetime access to all content • New modules added regularly
From Theory to Interview Performance
Understanding how to design a notification system is different from demonstrating that understanding in a 45-minute interview The architecture data model and scaling strategies you’ve learned represent the…
The Communication Layer Matters Most
Most candidates fail notification system interviews not because they lack technical knowledge but because they communicate poorly They jump into solutions without clarifying requirements They design components without…
Strong interview performance means externalizing your thought process State requirements before architecture Explain the purpose of each component as you introduce it Acknowledge trade-offs explicitly and defend your…
When your interviewer asks Why did you choose a message queue here the weak answer is Because it’s a common pattern or For scalability The strong answer is…
The Framework You Can Reuse
This article walked through notification system design but the framework applies to almost any distributed system interview The pattern is consistent clarify scope state functional requirements define quality…
Practice this framework with other classic problems Design a URL shortener using the same structure clarify read vs write ratio custom URLs analytics requirements create short URLs redirect…
The specific components change. The approach remains constant. Master the framework and you can tackle unfamiliar problems confidently because you have a structured way to explore them.
Common Mistakes to Avoid
After conducting over 150 mock system design interviews, I’ve observed consistent failure patterns. Avoid these and you immediately outperform most candidates.
Jumping to implementation too quickly. Candidates start discussing Redis configuration or Kafka partition settings before establishing requirements Tools are implementation details First define what the system must accomplish…
Ignoring failure scenarios. Weak candidates design happy paths Strong candidates design for failure External APIs timeout Networks partition Databases become unreachable Your notification system must handle these scenarios…
Treating all notifications identically. OTPs and marketing emails have completely different requirements OTPs need sub-minute delivery and high reliability Marketing emails can process over hours with best-effort delivery…
Neglecting observability. Production systems need monitoring logging alerting and tracing Candidates often design architectures without explaining how operators would understand system behavior debug issues or respond to incidents…
The Practice Component
Reading this guide provides knowledge. Applying it under interview pressure requires practice. The gap between understanding concepts and performing in real-time is where most candidates struggle.
Practice by recording yourself designing systems Set a 45-minute timer Pick a problem Design it out loud explaining your reasoning as if an interviewer were listening Review the…
This self-review process reveals communication gaps that silent study never exposes You might understand idempotency perfectly but struggle to explain it concisely under time pressure Identifying that gap…
📥 Download: System Design Interview Preparation Checklist
This printable checklist guides you through the complete interview framework from initial clarification through scaling discussions Use it during practice sessions to ensure you’re covering all critical aspects…
Download PDFBeyond Notification Systems
This article focused on one specific problem but the principles transfer Clarifying ambiguous requirements matters for rate limiters chat systems and video streaming platforms Stateless architectures enable horizontal…
Study the patterns not just the specific implementation When you encounter a new system design problem ask yourself Is this primarily read-heavy or write-heavy Where are the consistency…
Your Next Steps
If you’re preparing for system design interviews you now have a complete framework for notification systems Apply it immediately Design a notification system from scratch using this article…
Then expand to other problems Design a distributed cache Design a social media feed Design a ride-sharing dispatch system Apply the same framework clarify requirements architecture components scaling…
For engineers who want structured guidance, expert feedback, and realistic practice, geekmerit.com provides comprehensive preparation specifically for senior developers The course covers notification systems alongside 20 other design problems…
The Real Test
Ultimately system design interviews test your ability to think through complex problems systematically make principled trade-offs and communicate technical decisions clearly These skills matter more than knowing every…
A candidate who methodically clarifies requirements states assumptions explicitly designs simple solutions that address stated needs and discusses trade-offs honestly will outperform someone who memorizes complex architectures but…
Notification systems are common interview problems because they naturally surface these evaluation criteria They require asynchronous processing external service integration retry logic user preferences multiple delivery channels and…
Master this problem not by memorizing this specific architecture, but by understanding the reasoning behind each decision. That understanding transfers to every system design interview you encounter.
Frequently Asked Questions
What’s the difference between designing a notification system for an interview versus production?
Interview designs focus on demonstrating systematic thinking and trade-off analysis within 45 minutes Production systems include operational concerns like monitoring dashboards deployment strategies disaster recovery and cost optimization…
Should I mention specific technologies like Kafka or RabbitMQ by name?
Mention technologies after establishing requirements and explaining what properties you need from that component Say We need a distributed message queue that supports partitioning for parallel processing and…
How do I handle it when the interviewer changes requirements mid-interview?
Requirement changes test your adaptability Don’t start over from scratch Instead identify which parts of your existing design still work and which need modification If the interviewer says…
What if I don’t know the answer to a specific technical question during the interview?
Admit what you don’t know then demonstrate how you’d figure it out If asked about a specific retry algorithm you haven’t used say I haven’t implemented that specific…
How much time should I spend on each section during a 45-minute interview?
A rough guideline 5 minutes clarifying requirements 5 minutes stating functional and non-functional requirements 15 minutes designing high-level architecture and walking through key flows 10-15 minutes drilling into…
Is it better to design a simple system well or attempt a complex system but make mistakes?
Design the simplest system that meets stated requirements then extend it if time permits A complete well-reasoned simple design outperforms an incomplete complex design every time Interviewers can…
Citations
- https://aws.amazon.com/sns/
- https://kafka.apache.org/documentation/
- https://www.twilio.com/docs/usage/api
- https://sendgrid.com/docs/API_Reference/index.html
- https://firebase.google.com/docs/cloud-messaging
- https://developer.apple.com/documentation/usernotifications
- https://www.rabbitmq.com/documentation.html
- https://redis.io/documentation
Content Integrity Note
This guide was written with AI assistance and then edited, fact-checked, and aligned to expert-approved teaching standards by Andrew Williams . Andrew has over 10 years of experience coaching software developers through technical interviews at top-tier companies including FAANG and leading enterprise organizations. His background includes conducting 500+ mock system design interviews and helping engineers successfully transition into senior, staff, and principal roles. Technical content regarding distributed systems, architecture patterns, and interview evaluation criteria is sourced from industry-standard references including engineering blogs from Netflix, Uber, and Slack, cloud provider architecture documentation from AWS, Google Cloud, and Microsoft Azure, and authoritative texts on distributed systems design.

